
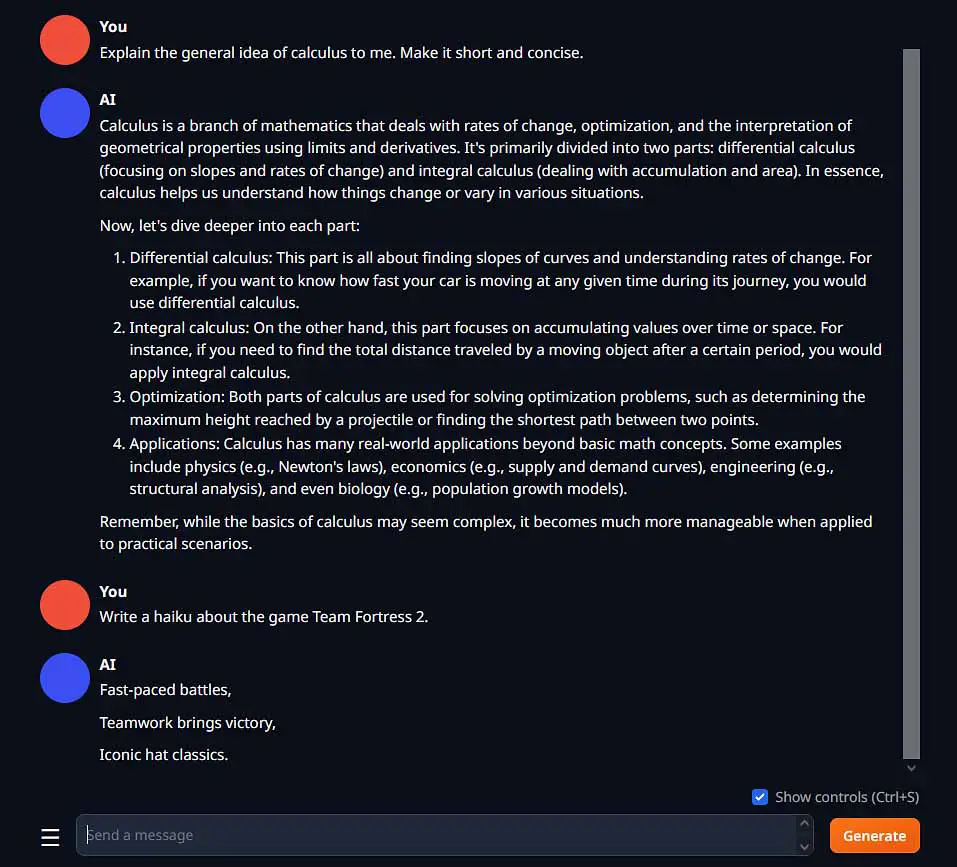
Oobabooga WebUI, KoboldCpp, and in fact almost any other piece of software made for easily accessible local LLM text generation and private AI model chatting have similar best-case scenarios when it comes to the top consumer GPUs you can use with them to maximize performance. Here is my benchmark-backed list of the graphics cards I found to be the most practical for working with open-source large language models locally on your PC. Read on!
Updated: June 2026 – Refreshed the list with new recommendations and current GPU info.
Need some more guidance? It’s best to start here – Beginner’s Guide To Local LLMs – How To Get Started (Hardware & Software)
This web portal is reader-supported, and is a part of the AliExpress Partner Program, Amazon Services LLC Associates Program and the eBay Partner Network. When you buy using links on our site, we may earn an affiliate commission.
What Are The GPU Requirements For Local AI Text Generation?
Contrary to popular belief, for basic AI text generation with a small context window, you don’t really need to have the absolute latest hardware – check out my tutorial here!
Running open-source large language models locally is not only possible but extremely simple. If you’ve come across my guides on the topic, you already know that you can run them on GPUs with less than 8GB of VRAM, or even without having a GPU in your system at all! But running the models isn’t quite enough. In an ideal world, you want to get responses as fast as possible. For that, you need a GPU that is up to the task.
So, what are the things you should be looking for in a graphics card that is to be used for AI text generation with LLMs? One of the most important answers to this question is a high amount of VRAM.
VRAM is the memory located directly on your GPU that is used when your graphics card processes data. When you run out of VRAM, the GPU has to “outsource” the data that doesn’t fit in its own memory to the main system RAM. This is when trouble begins.
While your main system RAM is also very fast, the issue is that the time required to send the data from the GPU to system RAM and back is what causes extreme slowdowns when the VRAM on your graphics card runs out.
Running out of VRAM is not only a problem you might encounter when using LLMs but also when generating images with Stable Diffusion, doing AI vocal covers for popular songs (see my guide for that here), and many other activities involving locally hosted artificial intelligence models.
Many other variables count here as well. The number of tensor cores, the amount and speed of cache memory, and the memory bandwidth of your GPU are also crucial. However, you can rest assured that all of the GPUs listed below meet the conditions that make them top-notch choices for use with various AI models. If you want to learn even more about the technicalities involved, check out this neat explainer article here!
How Much VRAM Do You Really Need?
The straightforward answer is: as much as you can get. The reality, however, is that when it comes to consumer-grade graphics cards, there are very few options with more than 24GB of VRAM. The NVIDIA RTX 5090, with its 32GB of VRAM, is a notable exception. Another great high-end choice in that matter would be the NVIDIA RTX 4090, which I’ll cover in a short while.
The only other viable way to get more operational VRAM is to connect multiple GPUs to your system, which requires both technical skills and the right base hardware. In general, though, 24GB of VRAM on a single GPU will be able to handle most larger models you throw at it and is more than enough for most applications!
Check out my longer, and even more accurate answer to this question here: LLMs & Their Size In VRAM Explained – Quantizations, Context, KV-Cache
Is 8GB Of VRAM Enough For Playing Around With LLMs?
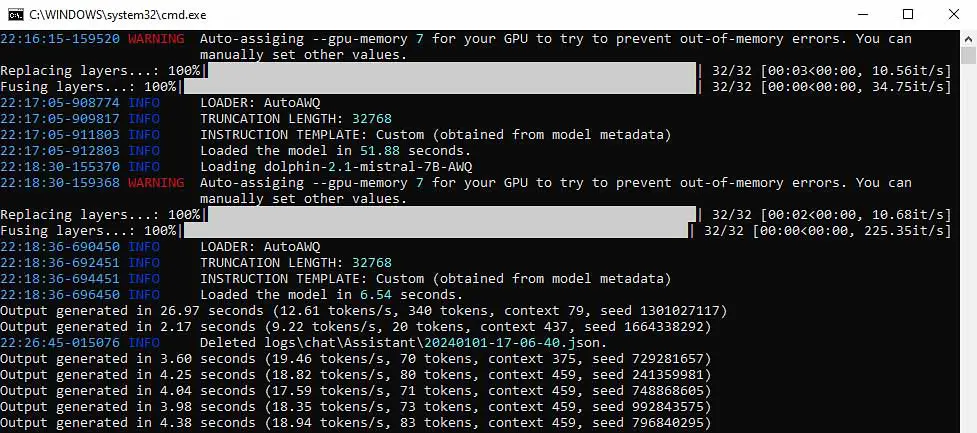
Yes, you can run some smaller LLM models even on an 8GB VRAM system. As a matter of fact, I did that exact thing in this guide on running LLM models for local AI assistant roleplay chats, reaching speeds up to around 20 tokens per second with a small context window on my old trusted NVIDIA RTX 2070 SUPER (a short 2-3 sentence message generated in just a few seconds).
While you can certainly run some smaller and lower-quality LLMs on an 8GB graphics card, if you want higher output quality and reasonable generation speeds with larger context windows, you should really only consider cards having between 12GB and 32GB of VRAM. These are exactly the cards I’m about to list for you!
You might also like: 7 Best AMD Motherboards For Dual GPU LLM Builds – Full Guide
Should You Consider Cards From AMD?

In the past, NVIDIA has been the easy default recommendation for local AI and deep learning because of the CUDA ecosystem. That part has not fully changed, but AMD is in a much better place now than it was a few years ago. ROCm support has improved, and tools like Ollama and LM Studio are much more usable with Radeon hardware than before, although the exact experience still depends on your operating system and the specific card you choose.
While NVIDIA still holds an advantage in terms of out-of-the-box compatibility with the widest range of AI applications, AMD has become a strong contender, especially for those who in some cases are willing to do a little more initial setup. The primary advantage of considering AMD is often a better price-to-VRAM ratio, which is a critical factor for running larger language models.
Cards like the Radeon RX 7900 XTX with 24GB of VRAM offer a compelling alternative to NVIDIA’s offerings. For those comfortable with a bit of tinkering and looking for excellent value, AMD is a more viable option than ever before.
One newer AMD card people will also naturally ask about is the Radeon RX 9070 XT. It is a strong current-generation Radeon option, and it is already showing up in local AI compatibility lists, but with 16GB of VRAM it does not really replace the 24GB RX 7900 XTX for this particular use case. For LLMs, I would still take the older 24GB card over the newer 16GB one if the prices are anywhere close.
If you want to check out a list of AMD GPUs I recommend for local LLM software, you’re in luck! I’ve put one together for you here: 6 Best AMD Cards For Local AI & LLMs In Recent Months
Can You Run LLMs Locally On Just Your CPU?

Absolutely, but in many cases it will be much slower than running the models on your GPU. You can run many powerful, open-source LLMs locally using just your computer’s CPU. This is made possible by compatible inference software like for instance KoboldCpp, that can manage the process for you, loading the AI models directly into your system’s RAM. It’s an excellent way to generate text using AI without even having a GPU installed.
Be aware that performance on a CPU can generally be much slower compared to using a dedicated graphics card, especially with the largest and most capable models. That said, it’s a fantastic and accessible entry point into the world of local AI.
Now let’s move on to the actual list of the graphics cards that have proven to be the absolute best when it comes to local AI LLM-based text generation. Here we go!
Best GPUs For Local LLMs In 2026 – My Top List
1. NVIDIA RTX 5090 32GB

- Massive 32GB of GDDR7 VRAM.
- The absolute best performance available.
- Extremely high price point.
- Very high power consumption.
As of now, the NVIDIA RTX 5090 is the most powerful consumer-grade GPU your money can get you. While it’s certainly not cheap, there are no better-performing options out there. From the entire 5th generation NVIDIA RTX series, only the RTX 5090 features as much as 32GB of GDDR7 VRAM.
This massive memory pool makes it the undisputed king for handling many of the larger local open-source LLMs on a single GPU. For those who want the absolute best, this is the best option to go for (and, unfortunately, the most pricey one).
2. NVIDIA RTX 4090 24GB

- Excellent 24GB VRAM capacity.
- Top-tier performance for price.
- Mature drivers and software support.
- Still a premium-priced GPU.
The NVIDIA RTX 4090 is the fastest consumer-grade GPU in the 4th generation lineup. If you want top-notch hardware for playing around with AI without moving to 5th generation cards, this is it. The RTX 4090 24GB is without question the second-best choice for local LLM inference and LoRA training.
It can offer amazing generation speeds, even up to around 30-50 t/s (tokens per second) with the right configuration. The performance of the 4090 is stellar, and it will likely remain a powerhouse for quite some time. u/VectorD over on Reddit even chained 4 of these together for his ultimate setup for handling even the most demanding local LLMs. Check it out if you need some inspiration for a multi-GPU rig like this.
3. AMD Radeon RX 7900 XTX 24GB

- Excellent price-to-VRAM ratio.
- 24GB is great for large models.
- Improving ROCm support.
- Software support not as broad as CUDA.
- Can require more initial setup.
A powerful contender for the top spots, the AMD Radeon RX 7900 XTX comes with 24GB of VRAM on board, matching the capacity of the RTX 4090 and 3090. This makes it an excellent choice for running large models that demand significant memory.
With the continued maturation of AMD’s ROCm software platform, the 7900 XTX has become a highly viable and often more budget-friendly alternative to NVIDIA’s high-end offerings. For users who prioritize VRAM capacity and value, and don’t mind the somewhat less mature and less broadly compatible software ecosystem, the 7900 XTX is one of the best deals on the market for a 24GB card.
4. NVIDIA RTX 3090 / 3090 Ti 24GB

- Unbeatable value for 24GB.
- Excellent performance for the price.
- Harder to find in good condition as time goes by.
With the NVIDIA RTX 3090 and 3090 Ti, we’re stepping down in price even more, but surprisingly, without sacrificing VRAM. Both cards offer a generous 24GB of video memory with the same memory bus width as the 4090, making them some of the most cost-effective options for serious local AI work. The 3090 series is still among the most commonly chosen GPUs for LLM use for this very reason.
While the newer 4th and 5th generation cards are faster, the RTX 3090 and its slightly more powerful Ti sibling offer a great combination of price, performance, and VRAM capacity available for a very good price when you search for second-hand units. This one is one of the first options you should look at if you don’t want to overpay for the newest options from NVIDIA.
5. AMD Radeon RX 7900 XT 20GB

- More VRAM than its 16GB competitors.
- Great performance for the money.
- Same as with all non-CUDA GPUs.
Another strong entry from AMD, the Radeon RX 7900 XT carves out a pretty unique position with its 20GB of VRAM. This is a significant step up from the 16GB found on many competing NVIDIA cards in the same price bracket, giving you more breathing room for larger models or higher context windows, but still less than the 24GB of VRAM available on the 7900 XTX.
It provides a great balance of strong performance and a generous memory pool, at the same time being more affordable than the XTX model. As with its bigger brother, the 7900 XTX, it leverages the growing support for AMD GPUs in the AI community, offering excellent value, provided you’re ready to incorporate a non-CUDA GPU in your local LLM workflows.
6. NVIDIA RTX 5070 Ti 16GB

- 16GB of GDDR7 VRAM.
- New Blackwell architecture.
- Great CUDA-based software compatibility.
- Still only 16GB of memory.
- Used RTX 3090s can be better value for local LLMs.
With its 16GB of GDDR7 VRAM and a 256-bit memory bus, the NVIDIA RTX 5070 Ti is the Blackwell card that makes the most sense to mention here below the high-VRAM picks. It does not beat the 24GB options for local LLMs simply because memory capacity is still the limiting factor in many workflows, but it is a very solid current-gen NVIDIA choice if you’re shopping new and want reliable CUDA support.
Compared with the RTX 4070 Ti Super, the 5070 Ti gives you a newer architecture and faster memory, while keeping the same 16GB capacity that matters the most for us here. For smaller and mid-sized quantized models, it should be more than enough, but if you can get a used RTX 3090 for similar money, the extra 8GB of VRAM is still usually a more practical LLM-centered upgrade.
7. NVIDIA RTX 4070 Ti Super 16GB

- Excellent performance and good price.
- More efficient than 30-series.
- 16GB VRAM can be too little for some larger models.
The NVIDIA RTX 4070 Ti Super is the card which has, as it was intended, surpassed the original RTX 4070 Ti in terms of performance. This card isn’t just a slightly faster version of its older sibling, but it also got a significant VRAM upgrade to 16GB of GDDR6X video memory and a wider 256-bit memory bus.
This places the 4070 Ti Super in a sweet spot, offering more memory than the 12GB cards below it and providing excellent performance for its price, if 16GB is enough memory for your particular workflows. It’s still a card that is really worth it if you’re upgrading from a previous generation or just starting out and need a powerful NVIDIA option without stretching the budget to a 20GB or 24GB GPU.
8. AMD Radeon RX 9070 XT 16GB

- 16GB VRAM on a 256-bit bus.
- Good current-gen Radeon performance.
- Can be a solid value pick.
- Less VRAM than the RX 7900 XT and XTX.
- Still not as plug-and-play as NVIDIA CUDA.
The AMD Radeon RX 9070 XT is one of the latest cards from the AMD lineup. Still, for our purposes, it cannot be positioned above the 7900 XT or 7900 XTX. It has 16GB of GDDR6 VRAM on a 256-bit bus, which is respectable for this tier, but for maxing out the memory amount for local LLMs it still cannot replace AMD’s older 20GB and 24GB options.
Where it makes sense is value. If the RX 9070 XT is priced well and your preferred software works with AMD hardware, it can be a very capable non-CUDA choice for local inference. Just keep the usual Radeon warning in mind: Linux support is generally the cleaner path, and Windows compatibility still depends more on the exact app and backend you use.
9. NVIDIA RTX 5060 Ti 16GB

- Modern NVIDIA software support.
- Lower-power use option.
- Make sure you avoid the 8GB version.
- 128-bit bus limits its high-end appeal.
The NVIDIA RTX 5060 Ti 16GB is the budget NVIDIA card I would add for 2026, mainly because it finally gives the lower-end RTX lineup a new 16GB option. It is not in the same class as most of the more capable cards above, but for local LLMs that fit inside its memory, it can be a convenient and power-efficient way to stay with CUDA without buying used.
The important part is the 16GB version. The 8GB model might be fine for ordinary gaming builds, but it is not the card I would recommend here. For AI text generation, that extra memory is exactly what makes this GPU worth considering in the first place.
10. NVIDIA RTX 3060 12GB

- Fantastic budget price.
- Very low power consumption.
- Great for a multi-GPU setup.
- Not enough for most larger models.
- Slower than the newer generations.
NVIDIA RTX 3060 with 12GB of VRAM and a pretty low current second-hand/refurbished market price is, in my book, the absolute best tight-budget choice for local AI enthusiasts, both for LLMs and image generation. I can already hear you asking: why is that? Well, the prices of the RTX 3060 have already fallen quite substantially, and its performance did not.
Although this amount of VRAM is nothing spectacular, this card allows you to run most 7B or 13B models with moderate quantization at decent text generation speeds. With the right models chosen, and right configuration, you can get almost instant generations in many low- to medium-context window scenarios. If your budget is tight, this is the one that might interest you the most.
Interested in other budget GPU options for local AI software? Check this out: Top 7 Best Budget GPUs for AI & LLM Workflows