
If you’re using SDXL models for your image generations, the cause of this problem is quite simple. As you might already know, with Stable Diffusion XL checkpoints you’re able to use a refiner – an additional model meant to add more details to your image near the end of the generation process. Here is what it has to do with the issue.
SDXL Images Stop Generating at 80 Percent – The Reason
As the refiner in both the Automatic1111 WebUI, as well as in the Stable Diffusion Forge fork is by default set to kick in when the image generation process progress reaches 80%, and the refiner itself is simply a separate model that also has to be loaded into your GPU memory to be used, if you don’t have a sufficient amount of VRAM on your graphics card to accommodate both the main SDXL model you’re using and the compatible refiner or you don’t have your WebUI set up to do that, something peculiar happens.
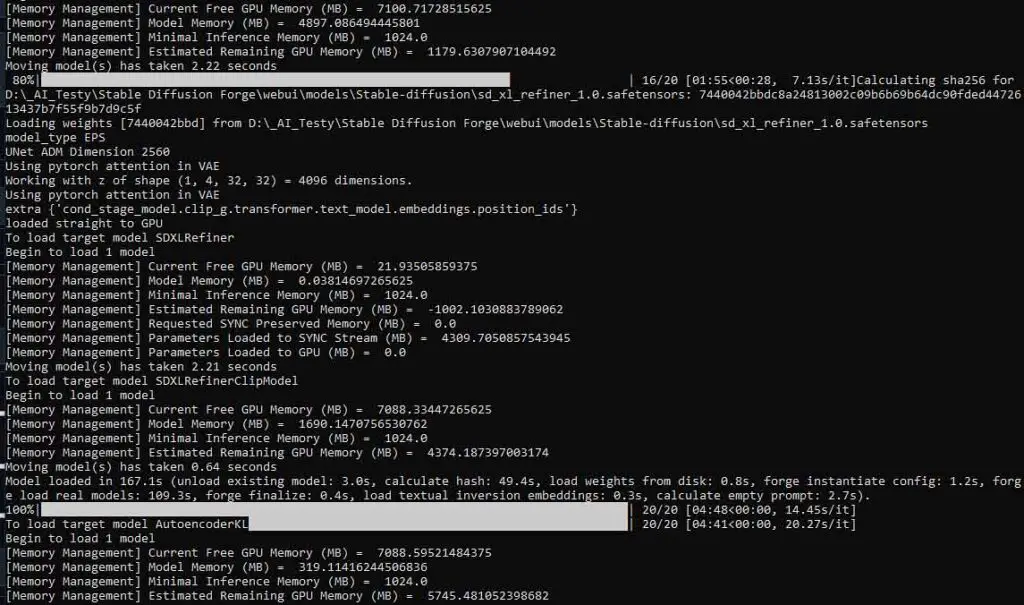
When the generation reaches the default set progress level at which the refiner should start to take hold and you’re short on GPU memory, your main SDXL model will have to be unloaded from the VRAM, and the refiner loaded in from your drive, taking its place. This is what in some cases can take quite a lot of time and make the WebUI hang on the 80% progress value.
What’s the solution then? Well, you need to either upgrade your GPU to one with enough VRAM to load in and fit both the SDXL checkpoint and the refiner model together, or if you can’t do that right away, make sure that both the SDXL model and the refiner files are placed on a fast SSD drive instead of an HDD. This can at the very least ensure that the loading and switching process will take as little time as possible each time it happens.
By the way, check out my curated list of the very best GPUs that are among the most recommended ones when it comes to running local AI software. They can even tackle hosting large high quality LLM models on your PC!
How To Load Both The SDXL Model and The Refiner Into VRAM In Automatic1111
If you have enough VRAM on your GPU to fit both of the models without running out of memory, you can easily make sure that Automatic1111 will always attempt to load them both together granting you much faster generation times than the ones you would face with the mentioned runtime model switching going on in the background. Here is how to do it:
- Go to the Automatic1111 WebUI settings menu.
- Enter the “Stable Diffusion” tab.
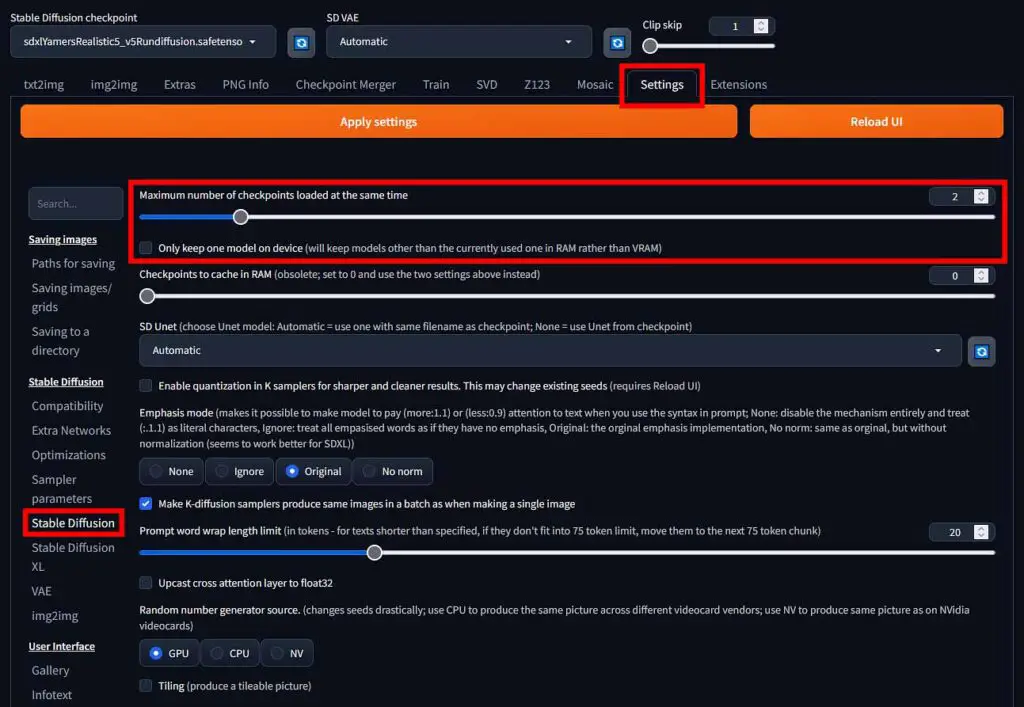
- Locate the “Maximum number of checkpoints loaded at the same time” – it should be on the very top. Set this value to “2”.
- Make sure that the “Only keep one model on device” box below is unchecked.
- Click the “Apply settings” button on top of the interface, and then the “Reload UI” button.
- After the WebUI refreshes, your newly chosen settings should now be active, and provided you have enough VRAM on your GPU, you should now be able to automatically load both the base SDXL model and the refiner into your graphics card memory and get faster image generation speeds.
Make sure that you only use this option if you’re sure that both the SDXL model you’re using and the refiner weights will fit in your graphics card memory. Otherwise, it may affect your generation times negatively.
You might also want to read: Stable Diffusion WebUI Stuck On “In Queue” (And 100% Disk Usage) Fix