
Since not that long ago you can run a small open-source Large Language Model on a PlayStation Vita, thanks to the efforts of the homebrew community. If you’re a fan of tinkering with handhelds and have a modded PS Vita lying around, you can now use it to generate short stories with a locally-run LLM. Let me show you what it’s all about.
You might also like: Buying a Used PS Vita for Homebrew – What You Need To Know
The psvita-llm Project – What It Is & How It Works
A developer known as “callbacked” has managed to run a modified version of Andrej Karpathy’s llama2.c on the handheld device, setting another example of truly low-spec AI inference.
To get an LLM running on the PS Vita, which only has about 512MB of RAM, a few clever things had to happen. The project, called psvita-llm, is a port of llama2.c, a simple C implementation for running LLaMA 2 models.
The code was adapted to work with the VitaSDK, the official toolchain for creating homebrew applications for the console.
The developer, callbacked, mentioned the process on Reddit:
“It was straightforward porting over the llama2.c inference code to work with the Vita’s syscalls, I used to work with C/C++ a lot so that helped too. I think I spent more time trying to make an interactive text interface that didn’t look too terrible!”
https://www.reddit.com/r/LocalLLaMA/comments/1l9cwi5/
The project includes a feature to download models directly on the device, so you don’t have to manually transfer files onto your PS Vita, which as some of you may know, can take quite a while.
The Model: What is TinyStories?
You’re not going to be running LLaMA 3 70B on a handheld from 2011. The key to this project is the choice of model: TinyStories.
It’s a special dataset and a series of models designed to answer the question: “How Small Can Language Models Be and Still Speak Coherent English?”, which actually is the title of the paper introducing TinyStories. The dataset was generated by GPT-3.5 and GPT-4 and consists of short stories using only the vocabulary of a typical 3 to 4-year-old.
The result is a collection of extremely small language models (some under 10 million parameters) that can still generate grammatically correct, coherent, yet simple stories. This makes them perfect for devices with very limited memory and processing power, like the PS Vita. The psvita-llm app lets you run two versions: a tiny 0.26M parameter model and a larger 15M parameter model.
You might also be interested in: LLMs & Their Size In VRAM Explained – Quantizations, Context, KV-Cache
Performance: How Fast Does It Actually Run?

So, you are able to run a local LLM on your Vita. Is it fast? Well, that depends on the model you choose. The developer provided some benchmarks on an overclocked PS Vita (PCH-1000 model), and the results are quite telling:
- TinyStories-260K (1MB file): Runs at approximately 120 tokens per second. This is impressively fast, producing text almost instantly.
- TinyStories-15M (60MB file): Runs at about 1.8 tokens per second. While much slower, it’s still usable and demonstrates that a more complex model can indeed run on the hardware.
These numbers are rather unsurprising, given how little memory the Vita actually has on board. The process is currently single-threaded, but the developer noted that a native multithreading solution could provide a significant performance boost in the future.
How To Get a Local LLM Running on Your Vita

If you have a modded PS Vita and want to try this yourself, the process is pretty simple. Here are the basic steps:
- Grab Your Vita: First, you’ll need a PS Vita running custom firmware. As of 2025, virtually any Vita model can be easily modded regardless of its firmware version.
- Download the VPK: Head over to the Releases page on the psvita-llm GitHub repository and download the .vpk file.
- Install It: Transfer the .vpk file to your Vita and install it using the VitaShell application.
- Download Models: The first time you launch the app, it will prompt you to download the TinyStories models. You can also manage (delete and re-download) models from within the app’s menu.
After that, you’re ready to start generating your first AI story on a handheld console!
What’s Next? From Local Inference to a Full Client – Vela
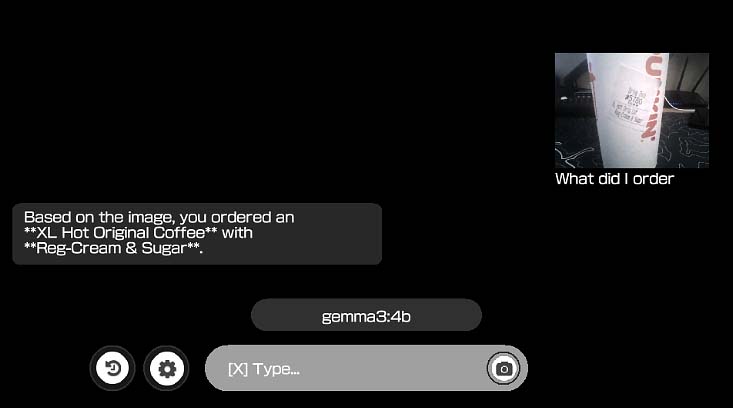
Running a model locally was just the beginning. The same developer has since released another project called Vela, which is a full-fledged LLM client for the PS Vita.
Instead of running the model on the device, Vela connects to external AI services using the Vita’s inbuilt wireless network module. This does allow you to interact with much more powerful models, including multimodal ones with image input features. Vela’s features include:
- Image Messaging: You can use the Vita’s camera to send images to models like GPT-4o.
- Chat History: Conversations are saved locally, and you can manage multiple chat sessions.
- On-Device Configuration: You can set up your API keys and endpoints directly in the app’s settings menu.
And that’s it! While this little project doesn’t have many practical applications, it’s a great example of how creative and active the homebrew community remains, even years after the PS Vita left the market. I hope you found this as interesting as I did! Until next time!
Want to know more about more recent portable retro gaming consoles which you can use for emulation? Check this out: 10 Best Retro Handheld Emulator Consoles This Year – My Personal Picks