
As a rule of thumb, usually you can estimate the required VRAM by considering the model’s parameter size, quantization level, and adding about 20% overhead for runtime allocations like KV cache and context window. However, for more complex scenarios or for those who want more precise numbers, there are several excellent VRAM calculator tools available online. Here are eight of the best I’ve come across and tested.
You might also like: Best GPUs For Local LLMs This Year (My Top Picks)
Quick Reference, and The Ones I Use
- The Apxml Calculator – great visual interface, easy parameter input, and a neat token generation speed simulation feature. Shows approximate memory usage both for inference and model fine-tuning.
- HF-Accelerate Model Memory Calculator – lets you import model parameters straight from the Hugging Face hub, and provides reasonable estimates for both inference and full training.
- Peng’s VRAM & GPU Requirement Calculator – perfect for planning out large-scale multi-GPU deployment scenarios, provides clear infrastructure examples to start off with.
How I Assessed Each of The Tools on This List
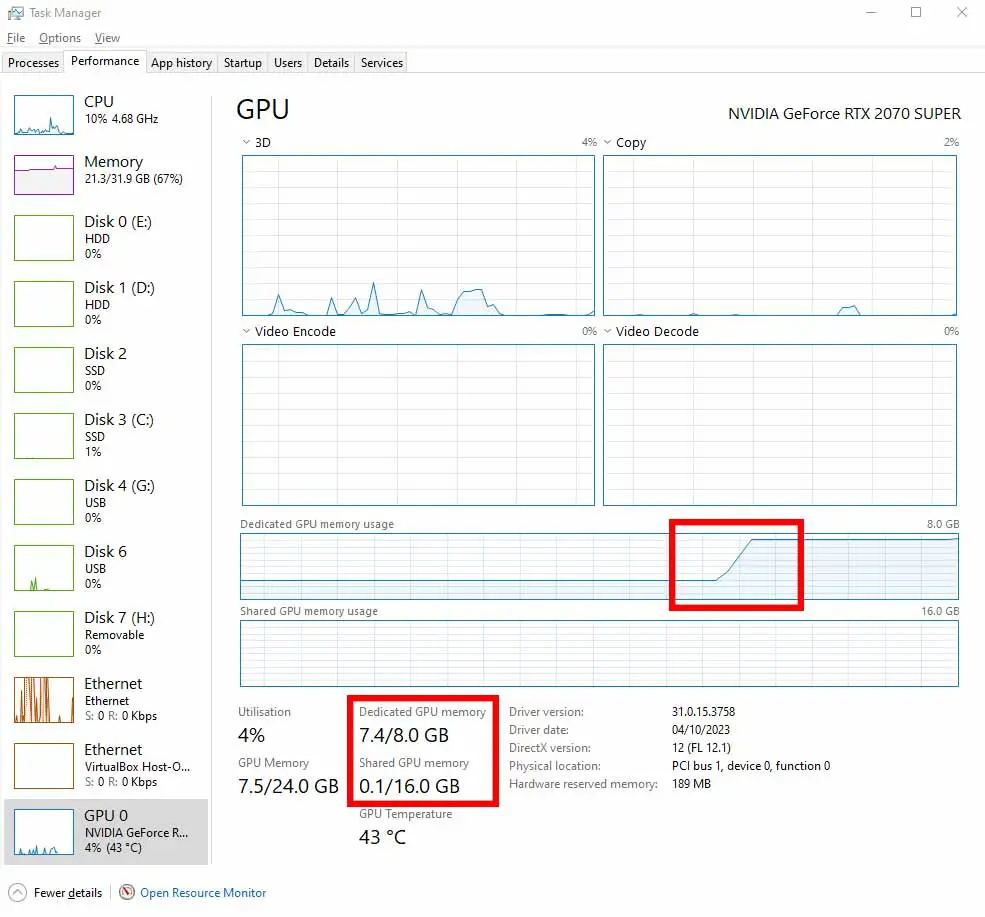
To run an open-source Large Language Model (LLM) efficiently on your own hardware, you need to ensure that the model and all its operational data fit within your GPU’s video memory (VRAM). The total VRAM usage depends on several factors, including the model’s size (number of parameters), the precision level or quantization method used, the length of the context window, and the size of the key-value (KV) cache.
You can learn much more about LLM GPU memory usage here: LLMs & Their Size In VRAM Explained – Quantizations, Context, KV-Cache
To quickly assess which of these calculators provides the most practical insight for an average user planning local inference on a chosen open-source LLM, I tested each tool individually by estimating the video memory usage required to run various 7–16B models with Q4 to Q8 quantization and 4096-token context windows, all loaded on an RTX 3090 Ti GPU.
For the most part, all tools returned similarly consistent results—as expected given the nature of their underlying estimation methods. Therefore, my focus shifted toward their unique quality-of-life features, such as preset model search functionality, and other usability aspects, including the ability of some of these to dynamically visualize the memory usage breakdown for each model component directly within the tool interface.
Additionally, many of these tools provide estimates not just for inference, but also for fine-tuning and full model training. These added capabilities can significantly speed up the planning process for local deployment. With that said, let’s move on to the first tool.
1. Apxml VRAM & Performance Calculator

The Apxml calculator tool is arguably one of the most popular calculators for large language models as of now. It allows you to input the appropriate model parameters and see how much memory or VRAM the model will require during inference or fine-tuning. What’s even better, it can also account for offloading some of the model’s data to CPU/RAM or an NVMe drive. Another unique feature is that it lets you simulate how fast the model will run on your setup by displaying example text output at an adjusted speed.
The tool is also accompanied by a neat write-up explaining how it works and performs calculations under the hood. It is updated fairly often, with the update log visible right below the calculator. Overall, if you need to quickly assess how much memory is required to locally host your chosen model, in my opinion, this is hands down one of the best and most reliable places to go.
2. Asmirnov VRAM Estimator
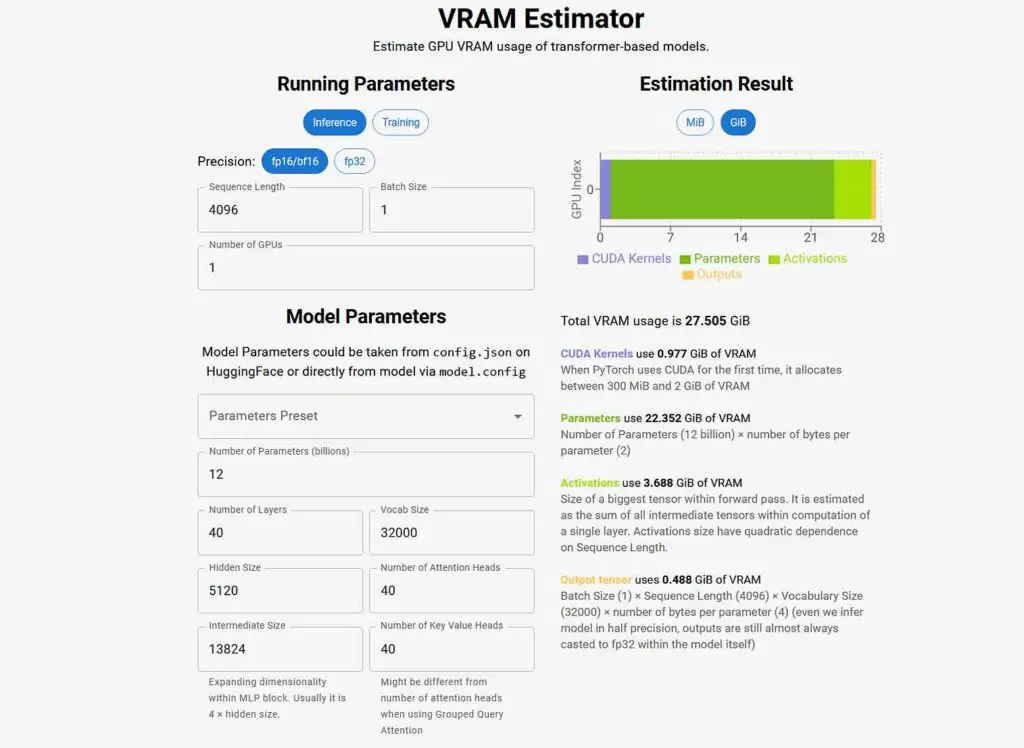
The VRAM estimator created by Alexander Smirnov is another one of the more popular solutions for quickly and reliably assessing how much video memory your chosen LLM will require, both for inference and training. It also features a simple and clear user interface and is supported by a detailed write-up explaining how it works.
The tool displays and explains each part of the model that is stored in memory. What’s even more interesting is that the calculation code behind it is open-source and accessible here. Overall, for me, it is the second-best calculator on this list in terms of simple and clear data visualization.
3. HF-Accelerate Model Memory Usage Calculator

The hf-accelerate model memory calculator, introduced by Zach Mueller and the creators of the popular Transformers library, Hugging Face Accelerate, lets you easily input any model name from a chosen Hugging Face repository and automatically calculates VRAM usage based on selected inference parameters.
You can simply paste the model name or URL of any model hosted on the Hugging Face Hub, and the calculator will instantly estimate the memory required for both inference and training. The only catch is that for gated models, you will need to provide your own Hugging Face access token for it to work.
Note: this one doesn’t let you input the exact model settings/parameters yourself, and you’re limited to selecting the models available on HF.
4. Deadjoe LLM Memory Calculator

This one is a bit different. The interface of the LLM memory calculator by Deadjoe is much more minimalistic, and the tool provides easy access to VRAM usage estimations for model training and inference, alongside with dynamically updated formulas used to calculate them.
In addition, you get a separate switch for estimates tailored to Apple Silicon devices with unified memory, a visual representation of the model memory blocks (not visible in the screencap above), and recommendations for the hardware needed to run a model with your chosen configuration. Neat and simple.
5. Vokturz “Can You Run It?” LLM Tool

The Vokturz “Can You Run It?” calculator works by letting you import models from Hugging Face but does not allow you to input the model parameters manually. In return, it offers an extensive GPU database provided by TechPowerUp and is transparent about the formula it uses for calculations — the one provided by EleutherAI, which I also reference in my LLM GPU VRAM usage guide.
A useful feature here is its ability to display both the amount of memory and the number of GPUs required for inference, LoRA fine-tuning, and full model training in different model quantizations, in a clear and easy to read chart. And that’s pretty much it when it comes to this one!
6. Peng’s VRAM & GPU Requirement Calculator

And here we have another tool, this time one that focuses solely on inference memory requirements. The VRAM & GPU requirement calculator created by Peng lets you choose from plenty of popular model presets or input the model parameter count and other inference settings yourself. It also lists all of the individual model’s in-memory components, as well as provides examples of different infrastructures needed to run popular open source LLMs.
Support for NVIDIA, AMD, Huawei Ascend, Mac M-series hardware, enterprise-grade GPU solutions, the ability to handle calculations for MoE models, as well as model throughput estimation, are all great features if you want to plan out an LLM deployment on virtually any modern infrastructure. Aside from the VRAM estimator, the website also contains an AI token generation speed simulator, much like the Apxml calculator, and a token counter and tokenizer tool.
7. Advanced LLM VRAM Estimator by Dariusz Wojcik

Another position on this list is the VRAM estimator made by Dariusz Wojcik which lets you put in your own model details to calculate the memory usage, or select an open-source LLM from a pre-defined list of popular and commonly used models.
The calculator mostly follows the 20% memory overhead rule, making all of the calculation details accessible via the drop-down menu at the bottom of the page. While it’s a very basic tool, it’s yet another option you can use for simple estimations with custom input model parameters.
8. Sam McLeod’s LLM vRAM Estimator
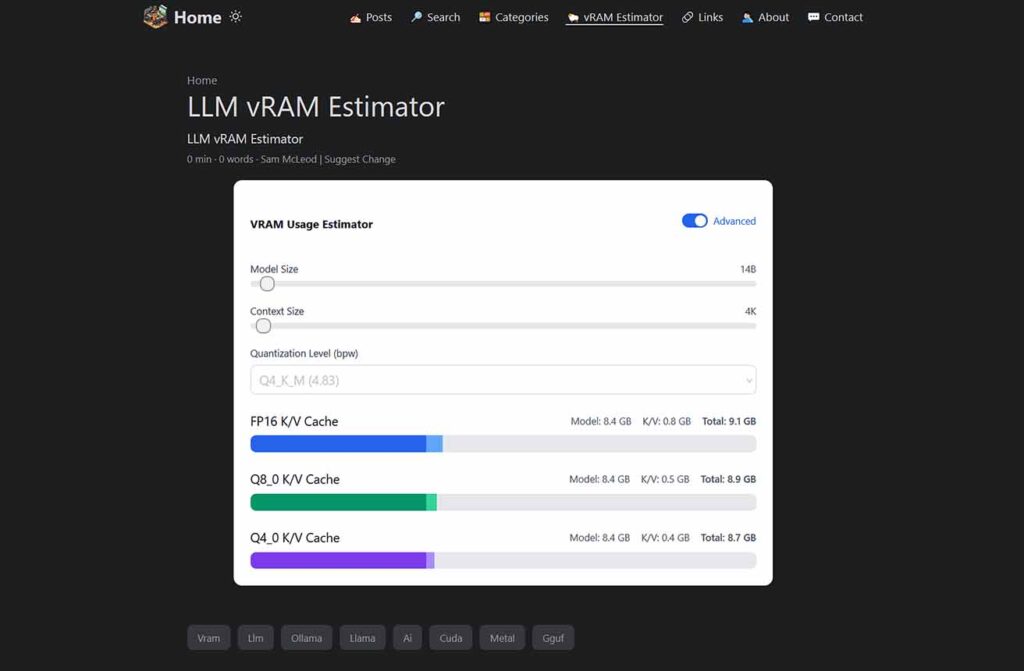
For a quick and simple memory usage estimation, this tool made by Sam McLeod is also a pretty good choice. It allows you to select a model size, context size, and quantization level to instantly calculate the VRAM usage for different K/V cache precision settings.
While it may not offer the same level of customization as some of the other calculators on this list, it’s perfect for getting a quick figure without getting bogged down in a mountain of different sliders and input fields. At the same time, that’s the very last tool on our list!
Why People Often Underestimate LLM Memory Usage

According to my observations and experience, it’s really easy to underestimate model memory usage during local inference, especially if you’re just beginning to explore the world of local LLMs.
VRAM requirements can grow quickly with changes in context length, precision, batch size, and runtime structures like the KV cache. A model that seems to “fit” based on your initial guess might crash during inference or perform poorly due to VRAM swapping or throttling. This often happens because a few important factors are omitted when making your first rough estimates.
Some of the Most Common Underestimations:
- Overlooking quantization impacts (higher precision = more VRAM)
- Assuming only model weights determine memory use (while ignoring KV cache, attention buffers, and intermediate activations)
- Forgetting to account for increased memory usage with larger context windows/longer conversations
- Misjudging the overhead for multiple concurrent inference threads
- Ignoring other software running in the background during inference potentially hogging a large chunk of your system’s memory.
Understanding these factors is crucial—especially when using low-VRAM consumer GPUs (8–12 GB). Luckily, the tools listed above can help you with just that.
In the end, with the right combination of model size, quantization, and context length, and with the help of the VRAM calculators, almost anyone can run a powerful LLM locally and use it for different purposes. For recommendations on the best GPUs for local AI, be sure to check out my guide on the best GPUs for local LLMs. Until next time!