
Dual-GPU builds with increased VRAM capacities are becoming increasingly popular within local LLM communities, with multi-GPU workflows gradually becoming more accessible to regular users, at least on the software side. There are quite a few things that you need to consider when aiming for a setup with more than one graphics card installed, but one of the most important choices you’ll have to make is which GPUs you’ll decide to pick. Here is all you need to know.
You might also like: Top 7 Best Budget GPUs for Local AI & LLM Workflows This Year
This web portal is reader-supported, and is a part of the AliExpress Partner Program, Amazon Services LLC Associates Program and the eBay Partner Network. When you buy using links on our site, we may earn an affiliate commission!
Quick GPU Model Reference List

Memory type: GDDR6X
Bus width: 384-bit
Bandwidth: ~936–1,008 GB/s

Memory type: GDDR6X
Bus width: 384-bit
Bandwidth: ~1,008 GB/s

Memory type: GDDR6
Bus width: 384-bit
Bandwidth: ~960 GB/s

Memory type: GDDR6
Bus width: 320-bit
Bandwidth: ~800 GB/s
What Else Do You Need For a Multi-GPU Setup?

Besides the graphics cards, you will need a few different things. And these are as follows:
- Compatible motherboard with sufficient amount of high-bandwidth GPU PCIe slots in the right configuration, and with the right amount of space between them and sufficient airflow, depending on the cards you’ll decide to pick.
- Power supply that will be able to provide power to all of the cards running at 100% speed.
- LLM inference software that has support for multiple GPUs – note that there are many ways of doing inference on multi-GPU setups. Most of the modern software like LM Studio or KoboldCpp and frameworks like llama.cpp and Ollama do support some form of distributing models across multiple GPUs.
These things are what’s necessary for you to start thinking about a professional and efficient multi-GPU setup aimed at locally hosted large language models.
Learn more here: 7 Best AMD Motherboards For Dual/Multi-GPU LLM Builds (Full Guide)
Main Benefits of a Multi-GPU Setup for Locally Hosted LLMs

A multi-GPU setup can accelerate both training and inference for large language models (LLMs) by enabling parallel processing across multiple graphics cards.
When it comes to training, it allows massive models and datasets to be split across devices, reducing overall computation time and making it feasible to handle models that exceed the memory limits of a single GPU. This distributed workload also improves throughput, allowing for larger batch sizes and faster convergence.
For inference, multiple GPUs can serve requests in parallel, reducing latency and increasing the number of simultaneous users or tasks that can be handled, depending on the parallel computing method used. And there are quite a few different ones as you can read in this summary writeup on the NVIDIA developer’s blog. I highly encourage you to read more about these, and then see if the inference software you decide to use supports the method that suits your use case most.
In addition to that, multi-GPU configurations offer better scalability when it comes to multi-user systems, although this probably won’t be useful to you when doing inference on your private equipment. Utilizing multiple GPUs can expand computing capacity of a larger-scale LLM deployment using appropriate frameworks.
Let’s get to another important topic – mixing two different graphics cards models together.
Can You Use Two Different GPU Models?
For most intents and purposes, yes. Using for instance one GPU manufactured by NVIDIA, and the other one by Intel in the very same system is feasible for most modern inference software including llama.cpp, which is pretty much a standard nowadays.
To see how this works, you can take a look at this practical example with an NVIDIA RTX 2070 and Intel Arc A770 using in llama.cpp with the Vulkan backend, reaching speeds of about 20 t/s when the model is split between the two cards.
Another neat example is this 2×3080 & 4090 setup with GPUs sourced from the Chinese market.
When using most multi-GPU compute methods, the overall inference speed is generally limited by the slowest GPU in the set. This limitation comes from the fact that the slowest device dictates synchronization points, causing faster GPUs to idle while awaiting data or task completion.
In this context, the factors that matter are not only the maximum GPU clock speed but also the memory bus width and its maximum throughput, as they affect how quickly data can be moved and processed across GPUs. Keep this in mind when deciding to use two different cards in your setup.
How Does Multi-GPU LLM Inference Work?
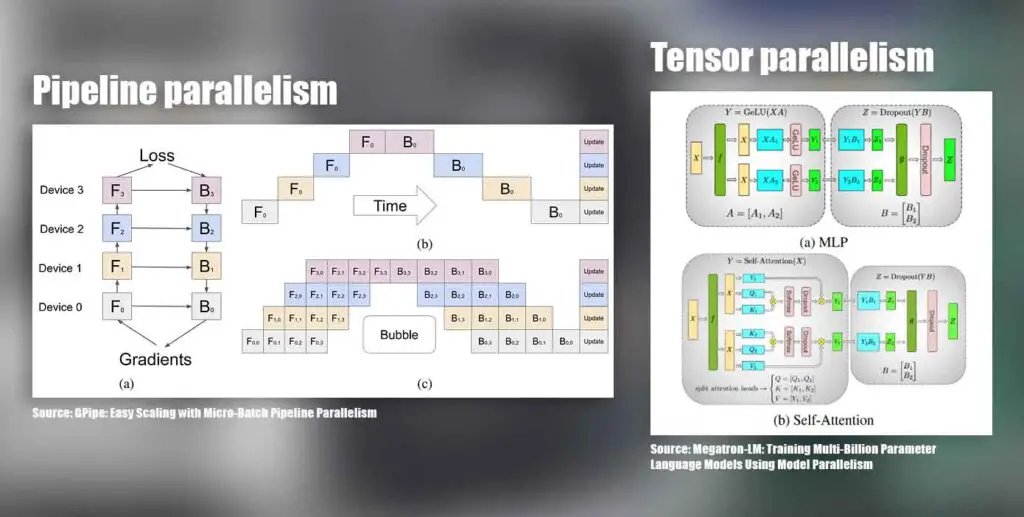
Most modern inference software like Ollama or LM Studio will automatically detect and use multiple GPUs, so from a setup perspective it really can be as simple as installing the cards and launching your model. The tricky part isn’t getting the GPUs recognized, but rather how the workload is distributed between them. Different software stacks often handle this in different ways, and the implemented parallel processing method has a big impact on performance.
The most common approach is model sharding, where the model is split into chunks (usually by layers), and spread across GPUs. In this setup, GPU #1 handles the first part of the forward pass, GPU #2 picks up where it left off, and so on. A type of model sharding approach is pipeline parallelism, and while it’s straightforward, it only gives you the benefit of having more memory to use during inference, and it can introduce sequential dependencies that can slow things down depending on the way it’s set up.
Another method is tensor parallelism, where the work inside a single layer is divided across GPUs. Each card crunches a slice of the math in parallel, and the results are stitched back together before moving forward. This keeps all GPUs busy at the same time and helps reduce bottlenecks caused by one card idling while another is still working. This is also the method which can offer some additional speed benefits in addition to the ability to use the combined VRAM pool of all your GPUs during inference.
Many frameworks like llama.cpp, vLLM, LM Studio, and KoboldCpp already support these methods (with different backend options like CUDA, ROCm, or Vulkan depending on your hardware). Which one you end up using should depend both on your chosen GPU setup and the software capabilities to handle parallel model processing.
Best GPUs For a Dual-GPU / Multi-GPU Local AI Setup
1. NVIDIA RTX 3090/Ti 24GB
- The RTX 3090 Ti has the same memory parameters as the RTX 4090
- One of the best cost-effective NVIDIA options out there
- Widely used in dual-GPU setups
- The production ended back in 2022 – mostly used cards remain on the market
- The availability might become an issue pretty soon
- VRAM amount: 24GB
- Memory type: GDDR6X
- Bus width: 384-bit
- Max. bandwidth:
- RTX 3090: ~936 GB/s
- RTX 3090 Ti: ~1,008 GB/s (1.01 TB/s)
The NVIDIA RTX 3090 as well as the 3090 Ti are hands down the most popular and the most cost-efficient solution if you want 24GB of VRAM, fast and wide memory bus, as well as a reasonably low prices on the second-hand market (as you can see, for instance here over on eBay).
A correctly configured setup with two 3090’s can grant you 48GB of VRAM, and there are already a lot of rigs utilizing this GPU combo to host LLMs locally. One example is this dual RTX 3090 Ti build by the user nero10578 over on the r/LocalLLaMA subreddit, another – this budget 4x RTX 3090 build by C_Coffie.
The speed differences between the base 3090 and the 3090 Ti are only about 10% according to most benchmarks, which makes choosing one over the other a matter of finding a reasonably good deal.
Check out also: NVIDIA GeForce 3090/Ti For AI Software – Still Worth It?
2. NVIDIA RTX 4090 24GB
- Great performance and fast video memory speed
- Also commonly used in multi-GPU inference setups
- A much more expensive option with pretty high price per 1GB of VRAM
- VRAM amount: 24GB
- Memory type: GDDR6X
- Bus width: 384-bit
- Max. bandwidth: ~1,008 GB/s
Going one level up, and at the same time into the 4th generation of NVIDIA GPUs, the NVIDIA RTX 4090 is another 24GB option on this list. Although it’s nowhere near as “affordable” as the older 3090’s, it is much more powerful. In terms of memory bus width and max bandwidth however, it’s in the exact same place as the RTX 3090 Ti.
Multi-GPU 4090 setups are also pretty common, like this 4x build by VectorD. If you can afford it, the 4090 is another great 24GB VRAM choice that might just be of interest to you.
3. NVIDIA RTX 5090 32GB

- Best performing GPU from the latest NVIDIA 5xxx lineup
- Almost double the memory bandwidth of the 4090/3090 Ti
- 32GB of VRAM is the highest amount you can get for now on a single consumer GPU
- Very high power usage (575 watts TGP)
- Current price makes it hard to seriously consider for a local multi-GPU setup
- VRAM amount: 32GB
- Memory type: GDDR7
- Bus width: 512-bit
- Max. bandwidth: ~1,792 GB/s
Upping the VRAM game, the NVIDIA RTX 5090 comes with 32GB of VRAM on board. This is all great, until you notice the price. While the 5090 is as of now one of the most powerful GPUs you can get on the consumer market period, it’s also one of the most expensive ones.
A dual RTX 5090 setup would grant you 64GB VRAM total, but also require a 1600W power supply at minimum. If you have the money and will to go for the absolute best hardware, this might be the right choice for you.
4. AMD Radeon 7900 XTX 24GB
- 24GB of VRAM for a very good price compared to NVIDIA GPUs
- Fast memory bus comparable to the base RTX 3090
- More video memory than the newer 9700 series have to offer
- No native CUDA support on AMD means worse software compatibility in some cases
- In certain contexts might be struggling to keep up with the latest NVIDIA cards
- VRAM amount: 24GB
- Memory type: GDDR6
- Bus width: 384-bit
- Max. bandwidth: ~960,0 GB/s
Following through with the AMD cards, the AMD Radeon 7900 XTX is the only new AMD GPUs with 24GB of VRAM. Yes, the new 9700 series don’t go this high in terms of the video memory department, and the XT that we’re going to talk about next, only features 20GB of on-board memory.
Dual 7900 XTX setups do work, and they are a great budget option if you need to save some money, provided that your software setup and use case does make using AMD GPUs for model inference a viable choice.
5. AMD Radeon 7900 XT 20GB
- A scaled down, cheaper version of the 7900 XTX
- Only a minor ~10-20% downgrade in performance
- 4GB VRAM less can be a major downgrade considering the price difference between the XT and the XTX
- No native CUDA support
- VRAM amount: 20GB
- Memory type: GDDR6
- Bus width: 320-bit
- Max. bandwidth: ~800 GB/s
The AMD Radeon 7900 XT is just a little bit less powerful than its XTX variant, with approximately 10-20% lower general benchmark scores on average according to corsair.com, as well as 4GB less VRAM.
It’s another great pick if you’re planning to build a dual GPU setup on a tight budget. If you want to to go even lower with the price, let’s move on to the Intel Arc GPU series.
6. Intel Arc A770 16GB

- 16GB of VRAM for less than $300 new is a very good deal
- One of the choices rising in popularity when it comes to multi-GPU homelab setups
- No native CUDA support
- The software compatibility is still not nearly as good as with NVIDIA cards
- VRAM amount: 16GB
- Memory type: GDDR6
- Bus width: 256-bit
- Max. bandwidth: ~560 GB/s
The Intel Arc A770 is a 16GB VRAM card from the Intel’s Alchemist GPU lineup, which is among the least expensive graphics cards you can get new as of now.
Although Intel Arc GPUs are not as popular as NVIDIA or AMD cards yet, they are an excellent true budget choice for multi-GPU builds with the right inference/training software setup. A dual A770 setup would grant you 32GB VRAM total, for a price of just about $600 for the cards alone.
Multi-GPU LLM setups with Intel Arc cards using IPEX-LLM have been officially confirmed to work on the Intel community forums, and the support for Intel GPUs in LLM inference software is rapidly evolving. If you need more inspiration, take a look at this model traning/fine-tuning cluster made using seven Intel Arc A770 GPUs.
Another worthwhile GPU from the Intel Arc series is the Intel Arc B580. While it offers only 12GB of VRAM, it’s more powerful, and can also be found for under $300 new.
When you take into account the current prices and performance of the Intel Arc cards, this is a very cost-efficient solution for a full-on dedicated LLM rig on a budget.
What Else Can You Use a Multi-GPU Setup For?
Of course you’re not limited to just running bigger LLMs on a multi-GPU rig. Having more than one graphics card opens up a lot of other interesting use cases, and if you’re building a system like this, it makes sense to squeeze out as much value from it as possible.
One popular option is splitting different workloads across your GPUs. For instance, you can dedicate one card to running your LLM and another to local Stable Diffusion inference software like StableSwarmUI for image generation. This way, you’ll be able to, for instance, chat with an AI model while simultaneously generating images without either workload slowing the other down or blocking it.
Another great example of efficiently using two GPUs in your system could be for instance running free local AI voice changer software like the w-okada live voice changer on your second card and gaming/streaming using your main GPU to avoid in-game slowdowns or dropped frames on stream.

Another use case is training or fine-tuning models locally. Even if you’re not working with full-scale datasets, multiple GPUs can speed up LoRA fine-tuning or custom embeddings dramatically, especially with training frameworks that support advanced methods of model parallelism.
If you’re into gaming or media work, you can also offload encoding, decoding, or rendering tasks to your secondary GPU while keeping the primary one fully dedicated to inference. Similarly, multi-GPU setups allow you to drive more monitors, run multiple VMs without making them share a single graphics card, and in general expand what your system can do in parallel.
Finally, for the homelab crowd, multi-GPU setups are great for cluster experimentation. You’ll see people build “mini farms” with several budget GPUs (like multiple Intel Arc A770s) to experiment with distributed inference, model serving, or training. This gives you a lot of flexibility to test out different software stacks with simpler workflows without needing to resort to using cloud resources.
A multi-GPU setup is not necessarily just about running the absolute largest LLM you can fit into memory, even though that seems to be the most popular reason people choose to use one these days. It’s also about running more things at once, scaling tasks better, and experimenting with the kind of workflows that a single GPU just can’t handle. Thanks for reading, and until next time!
Check out also: Beginner’s Guide To Local LLMs – How To Quickly Get Started