
Here you will quickly learn all about local LLM hardware, software & models to try out first. There are many reasons why one might try to get into local large language models. One is wanting to own a local and fully private, personal AI assistant. Another is a need for a capable roleplay companion or story writing helper. Whatever your goal is, this guide will walk you through the basics of local LLMs including hardware requirements, inference software options, and lightweight models to start with. Enjoy!
Autor’s note: Rest assured, as much as I love experimenting with large language models, this guide was, in fact, written by a human. Enjoy!
Check out also: Top 7 Best Budget GPUs for AI & LLM Workflows This Year
Quick Local LLM Glossary – Key Terms Explained
| Term | Meaning |
|---|---|
| LLM | Large Language Model – an AI model trained to process and generate natural language. |
| Local LLM | Model executed entirely on local hardware, not cloud-hosted. |
| VRAM | Your dedicated GPU memory – determines max model size for fast inference. |
| RAM | Main system memory – used for CPU inference or VRAM overflow. |
| Inference | Running a model to produce outputs (no training involved). |
| Quantization | Reducing the numerical precision of the model (e.g., Q4, Q8) to shrink its size and improve speed at some accuracy cost. |
| Context Window | Maximum tokens the model can retain in active conversation memory. |
| Token | Smallest text unit processed (usually ~3–4 characters in English). |
| Base Model | General-purpose pre-trained LLM without any specialization. |
| Fine-tune | A base model adapted to a specific domain or task via additional training. |
| Merge | A hybrid model combining multiple fine-tunes. |
| Offloading | Moving parts of the model between CPU (RAM) and GPU (VRAM), typically to the GPU for speed; to the CPU only when VRAM is insufficient. |
| GGUF / GGML / Safetensors | Common local LLM formats. GGUF is the current standard for optimized inference. |
| RAG | Retrieval-Augmented Generation. injecting external data into model context for improved accuracy. |
| Multimodal | Model capable of processing multiple data types (e.g., text + images). |
| Instruct Model | Fine-tuned to follow explicit natural-language commands. |
| Chat Model | Fine-tuned for conversational, multi-turn exchanges. |
| Completion Model | Predicts text continuation without instruction bias. |
Why Use Local LLMs in 2026?
In the age of language models as capable as GPT-5 from OpenAI, Gemini from Google, or Claude from Anthropic, one might wonder why people are still interested in running much smaller (although still very capable) models locally.
There are many answers to this question, but in general, the most important perks of a local setup fully owned by you alone include:
- 100% privacy with the right configuration – With a fully local LLM setup, no data will ever leave your computer unless you specifically let it. This means that you can be sure that you’re not going to be giving access to your data to any company, and you’re able to utilize your LLMs to work on sensitive or private information without worrying about unwillingly sharing this data with third parties.
- Circumventing censorship – As you might know, many, if not most popular large language models are heavily censored when it comes to both potentially dangerous, and sensitive content. While to some degree such censorship is in many cases justified, getting access to a model which doesn’t limit what you can use it for can grant much more freedom to a responsible user.
- High level of customization – With most of the currently existing examples of local LLM inference software you have lots of additional tools at your disposal. These can include advanced character creators for local RP, speech synthesis modules with voice cloning capabilities, support for multimodal models with local image recognition capabilities, and much more!
- Hundreds of open-source models to choose from – Once you fully get into the world of local LLMs you’ll quickly realize that you have a large amount of different worthwhile models and model merges to test out. It’s really worth it to try out a few different ones compatible with your hardware in the very beginning to see which one is the best for your use case!
As stated by ApX ML in their local LLM course resources:
“Perhaps the most significant advantage of running an LLM locally is privacy. When you use a cloud-based LLM service, the text you enter as a prompt, and often the text the model generates in response, is sent over the internet to servers owned by a third party. Depending on the provider’s policies, this data might be stored, analyzed, or used to improve their services.”
https://www.apxml.com/courses/getting-started-local-llms/chapter-1-introduction-large-language-models/why-run-llms-locally
So arguably, the most important argument here is just that – privacy. When we’re talking about what this looks like in practice, it’s pretty obvious that for more complex and broader-focused tasks, smaller, locally hosted LLMs may have a harder time achieving acceptable performance scores.
While that may be an issue for some, the added perk of not handing your information over to any third parties is, at least for me, way more important. It’s still worth pointing out that smaller large language models can be extremely efficient when it comes to more precise, less general tasks with well-defined scope (such as writing prompts, light text editing, basic NER, and so on).
Being able to do so much with these types of models with total freedom when it comes to inference settings and no filters on processed data is in my honest opinion exactly why you should be interested in learning how to use local inference software yourself.
Local LLMs – Realistic Expectations
There are many largely inaccurate assumptions when it comes to LLMs. The most important one is that supposedly, all of the smaller 1-12B large language models that can be run locally are virtually useless for most meaningful tasks. This couldn’t be further from the truth.
The reality, however, is that most likely regardless of the use context and hardware you run them on, smaller large language models won’t be able to:
- Perform well in loosely-defined general tasks and workflows without a sufficient amount of in-context learning efforts from the user (so in essence, without careful prompt crafting).
- Deal with high-level logical reasoning over structurally and linguistically complex content.
- Outperform larger commercial models such as GPT-5 or Gemini, which are much larger, more sophisticated when it comes to architecture optimizations, and are run on much more powerful hardware than an average consumer can put their hands on.
As accurately stated by Walter Clayton in his short writeup about local LLM reasoning limitations:
“(…) local LLM limitations show up fast once your use case involves any kind of decision-making, adaptation, or planning.”
https://blog.walterclayton.com/local-llms-limitations-adaptive-coaching/
Keeping all these limitations of smaller language models in mind, I still think that you should consider getting into local LLMs if you have any interest in the topic of AI, NLP, or large language models at all. It’s not only a great learning experience, but also a very quick and simple way to find out the actual limitations of the technology you’re dealing with, which can in turn let you utilize commercial LLMs much more efficiently if you decide that going local is not for you.
This can in turn not only help you better understand how LLMs work, but also still let you perform many simpler but still substantial tasks. Such as…
Best Use Cases for Small Local LLMs
Many smaller open-source large language models (1–12B parameters, depending on the task) can still perform exceptionally well when it comes to tasks such as:
- Text summarization (for instance summarizing YouTube transcripts or study notes).
- Generating image or video prompt ideas, or variations on image prompts for various AI content generators.
- RAG workflows on your documents.
- Simple NER on large text corpora.
- Sentiment analysis.
- Classification tasks (such as content moderation or spam detection).
- Data labeling.
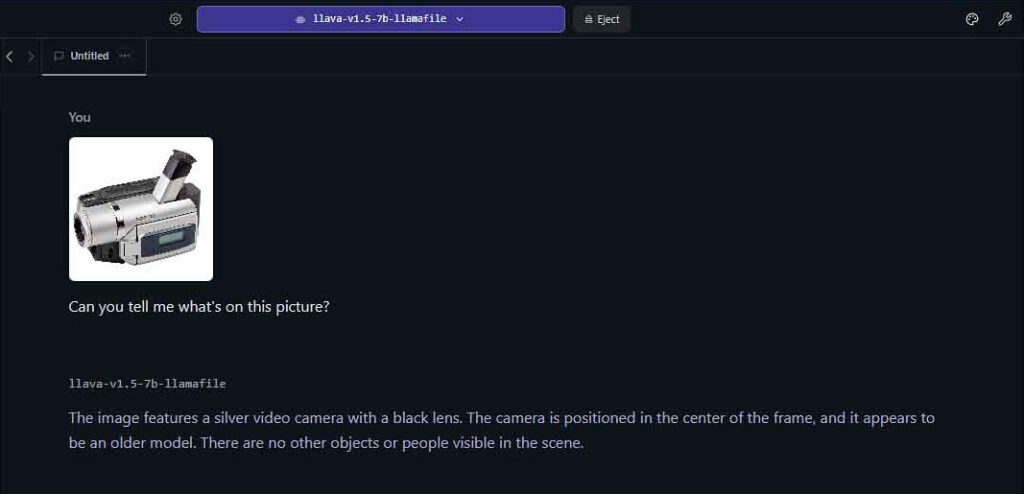
- Simple image description (with vision-enabled models such as LLaVA 7B).
- Generating storywriting prompts, or creating “choose your own adventure” stories.
- Translating large amounts of text data.
- Spell checking and grammar checks.
- Log file summarization.
- Converting date formats, structuring JSON data.
- Extracting data from structured documents or text files.
- Simple synthetic mock dataset generation.
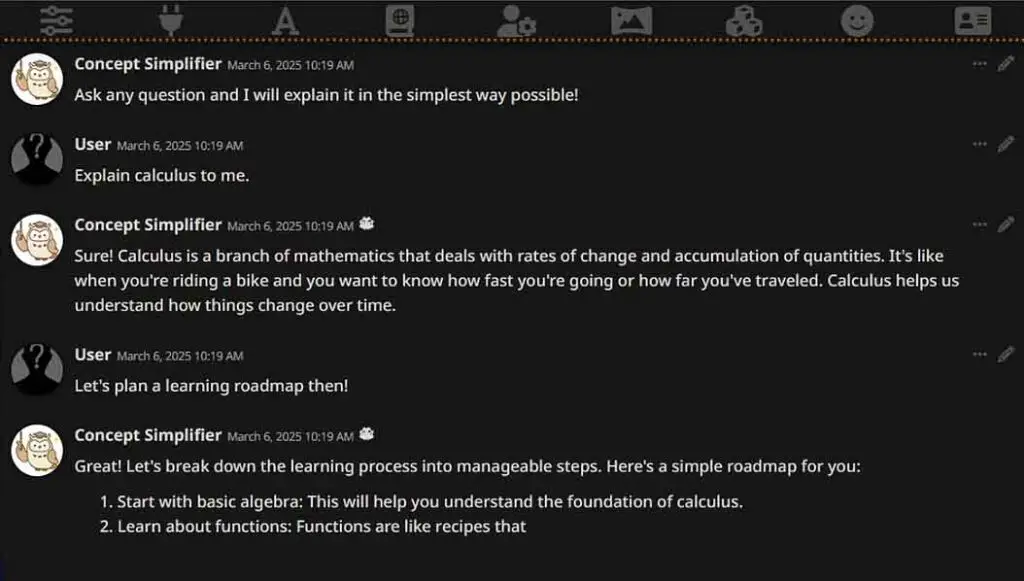
- Building learning roadmaps for various study topics.
- Local AI character roleplay (with much better user experience than character.ai, and fully uncensored).
- Chatting with an AI assistant in your native language (if you grab a model that is either fully pre-trained in or fine-tuned for conversations in your language).
- …and then some more.
While as I’ve already said, in the vast majority of cases smaller models won’t be able to reach either the accuracy or speed of models such as GPT-5 or Gemini Pro, the added perks of being in full control of your own data, as well as being able to customize your experience for your desired workflows, are among many valid reasons why you might choose to use them instead.
These are only some of the applications of local LLMs, and we’re going to further explore two of these which are arguably the most popular ones down below.
Two Routes – AI Assistants & Local AI Roleplay
As you might suspect there are two main routes that people take when researching local large language models and inference software.
These are in most cases either:
- Wanting to have a general-use ChatGPT-like local AI Assistant that they can use for various tasks such as creative text generation, text editing, reasoning and problem solving, simple NLP-related workflows and more.
- Being in need of a local AI roleplay/storywriting companion with the possibility of quick and easy customization of the simulated character personas, and additional tools to aid with these kinds of tasks.
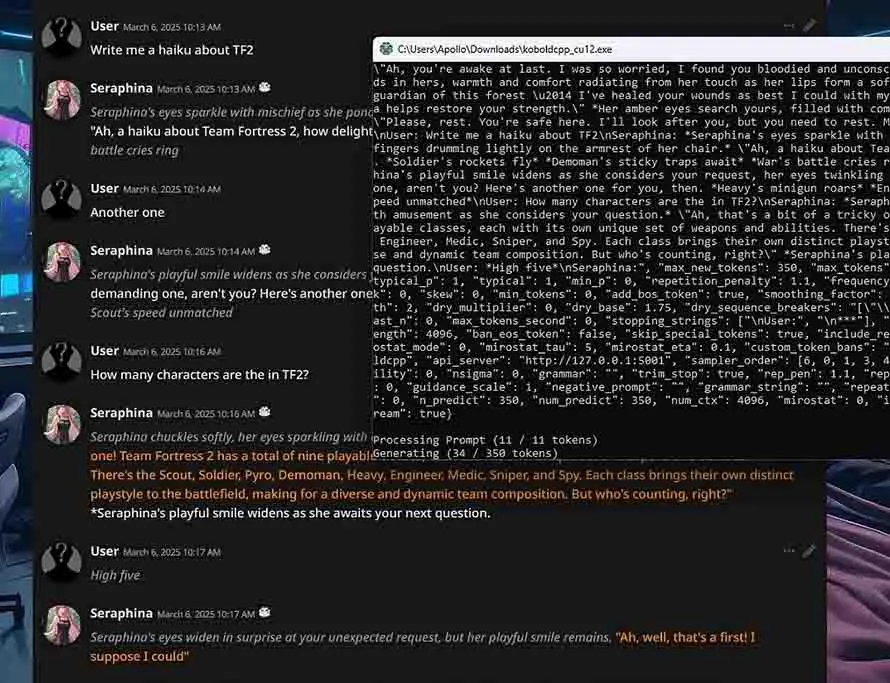
Both of these tasks can be easily achieved using the exact same inference software (each and every one of the positions from our little list here), however for local AI roleplay there exist even better solutions such as the KoboldCpp + SillyTavern combo which I have a complete tutorial for right here, or the OobaBooga WebUI.
Although the absolute smallest open-source LLMs available online (260K/15M parameters) can even run on an old PlayStation Vita, to locally host some more useful models you will need some better hardware.
Here is all you need to know about the hardware requirements for running large language models locally on your PC or a laptop.
Hardware Requirements – What Kind of GPU do You Need?

As I’ve already described in detail in my LLM GPU guide, while most GPUs with 8GB of VRAM or more will do for relatively quick inference on smaller, highly quantized open-source models, for the most freedom when it comes to which models you can efficiently use you want the highest amount of video memory (VRAM) you can get on your GPU for a reasonable price.
Check out my main LLM GPU guide here: Best GPUs For Local LLMs This Year (My Top Picks – Updated)
While CPU-only inference is possible, it can be really slow and inefficient when it comes to larger models. In an ideal situation, for the best performance you want your chosen model to fully fit within your GPU VRAM.
The model size in VRAM will depend on a few factors, including the number of model parameters, the data precision used (such as FP32, FP16, or INT8), the context window size, and the model’s quantization level. Higher parameter counts and less aggressive quantizations require more VRAM, while smaller models or those using advanced quantization techniques need less. Running larger context windows or models with high token capacity also increases VRAM demands because more intermediate results and KV-cache must be stored.
If you’re curious about how different text generation speeds in tokens per second (t/s) look, check out our dedicated simulator tool for a neat visualization: LLM Tokens-per-Second (t/s) Generation Speed Simulator
Given these variables, the general rule of thumb is: Get as much GPU VRAM as your budget allows, with 12GB+ being a good starting point for most use cases, and 24GB being even better for running larger models.
Rule of thumb: The more VRAM, the better.
- 12GB+ is a good starting point for most smaller, quantized models.
- 24GB+ is ideal if you want to run larger models comfortably.
When it comes to main system RAM, if you plan on offloading some data to it during inference for models that would otherwise not fit your GPU VRAM, or plan to do any CPU-only inference, you should go for the highest amount you can get for a good price. You never know when it might come in handy.
If you’re confused about terms like “model size” and “quantizations”, make sure to check out this resource I’ve put together quite recently: LLMs & Their Size In VRAM Explained – Quantizations, Context, KV-Cache
A Quick Word on Non-NVIDIA GPUs (Intel & AMD)
While NVIDIA graphics cards are the most popular option for local LLM users due to their native CUDA support, GPUs from AMD and Intel like the Radeon RX 7000 series or Intel Arc cards can still be solid, budget‑friendly options for local LLM work. These non‑NVIDIA cards in most cases will offer you much better prices with slightly reduced performance, and worse software compatibility.
“As Most developers of local LLM software (…) are prioritizing the CUDA framework when designing their projects as it was (and still is) one of the most widespread standards , NVIDIA cards will generally be the ones which work best with such software out of the box.”
https://techtactician.com/best-budget-gpus-for-local-ai-workflows/
It’s important to be aware that they may also require a little bit more tinkering during setup, depending on which software you’ll decide to use, due to lower compatibility with some AI libraries or inference tools. If you’re just starting out and want a smoother experience, NVIDIA might save you troubleshooting time, but don’t rule out AMD or Intel if you’re on a tight budget!
You can learn more about the latest AMD GPUs here: 6 Best AMD Cards For Local AI & LLMs
And about the latest Intel Arc cards, here: Intel Arc B580 & A770 For Local AI Software – A Closer Look
What About Multi-GPU Setups?

Given you’re set on being able to run some of the larger and more capable LLMs locally, you might like the idea of combining the VRAM pools of two or more GPUs together, to achieve a setup with more video memory that would be available to you on a single consumer GPU.
In general, it’s a good idea, provided that you:
- Have a compatible motherboard that has enough high-bandwidth slots (and sufficient spacing between them) to handle two or more GPUs running together.
- A power supply that will be able to provide enough juice to all of the GPUs in your setup at peak usage.
- And a software setup that can benefit from a multi-GPU setup (for instance LM Studio which we cover down below, that can handle multiple GPUs automatically, albeit without the additional benefits of tensor parallelism).
You might also like: 6 Best GPUs for Dual & Multi-GPU Local LLM Setups
Running LLMs on a multi-GPU setup can be extremely beneficial when it comes to multi-user inference scenarios as well as model training and fine-tuning, but it can also grant some speedups in a single-user setup, depending on the methods your inference software uses to split the inference workflow between the available GPUs.
The most important benefit of a multi-GPU setup for local large language models is not the potential speed boost, which can depend on many factors, but rather the combined VRAM capacity. This greater VRAM capacity allows users to run and explore much larger models than would be possible on a single consumer GPU.
You can read much more about motherboards fit for a dual-GPU setup here: 7 Best AMD Motherboards For Dual GPU LLM Builds (Full Guide)
How To Do This Without a GPU?

Rather easily – just install your chosen software mentioned below or on this list. They should all support CPU-only inference just fine. There is just one catch.
CPU-only inference relies on the model data being transferred between your CPU and main system RAM for calculations made while you wait for the model to output generated text.
This can be substantially slower than when the data needs to be moved only within the constraints of your GPU which uses its VRAM memory to temporarily store the model data during inference.
With that said, on systems without a sufficiently powerful graphics card (which generally translates to any relatively recent GPU with more than 8GB of VRAM on board), you can easily rely on your CPU & RAM combo sacrificing speed for the ability to run LLMs locally.
If you want to learn about some budget GPU options, make sure to check out my other guide on just that here: Top 7 Best Budget GPUs for AI & LLM Workflows This Year
Best Local LLM Software to Get Started With
There are plenty of options when it comes to local inference software, and most of them are actually very easy to use, featuring one-click installers for Windows, Linux, and Mac, allowing you to start using your chosen open-source models right after setup.
Here are in my opinion the best options for all of the most popular routes you can take if you’re just starting out.
LM Studio – The Easiest Way For Windows, Linux & Mac
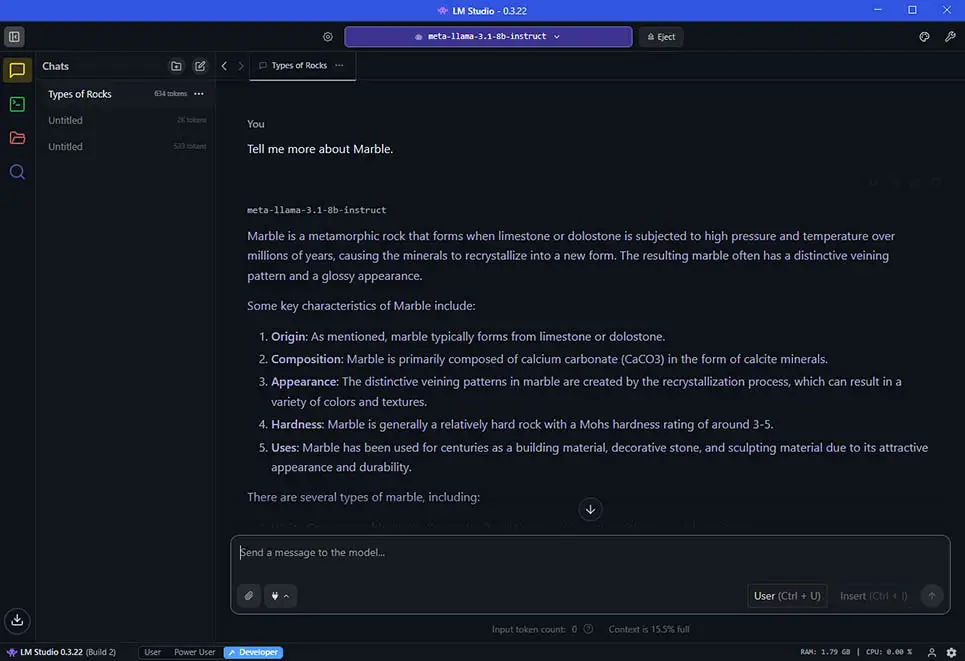
One of the very best and easiest ways to get started with local large language models is LM Studio. It features a simple one-click installer and an easy-to-use software interface, where you can access a few different modes depending on your level of expertise.
Using LM Studio to host your very first open-source LLM involves installing the software, choosing a model from the built-in model selection tool, which will automatically download and prepare your model for inference, and then using the integrated chat interface to begin a conversation with the model. You can do all this in less than five minutes if you’re quick!
If you feel more tech-savvy and prefer to lean toward programming simple apps using local LLMs, rather than simply using the models as your private all-in-one AI assistants, another tool offers a different approach.
Ollama – For The More Tech Savvy
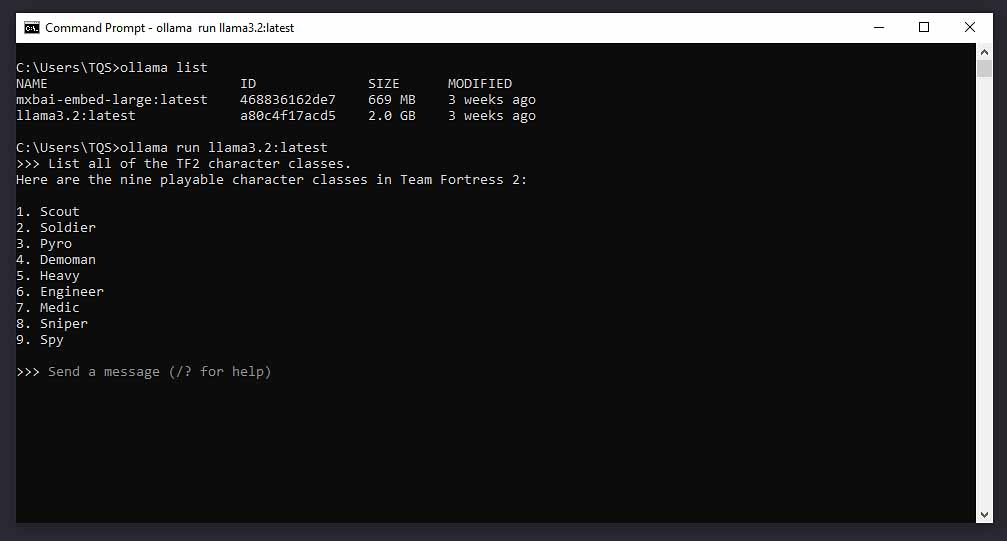
Ollama is an open-source platform that is a little bit different from LM Studio. First, by itself, it doesn’t feature a graphical user interface and is a command-line tool. Second, it’s mostly used as a backend for LLM-based software, rather than a fully featured LLM AI assistant chat client.
If you plan to develop your first LLM-based app, or you want to take the more raw approach and you already have some technical background, Ollama is a great option to start with, with broad hardware compatibility and great performance for both CPU and GPU model inference.
KoboldCpp + SillyTavern – A Character.ai Alternative for Local RP
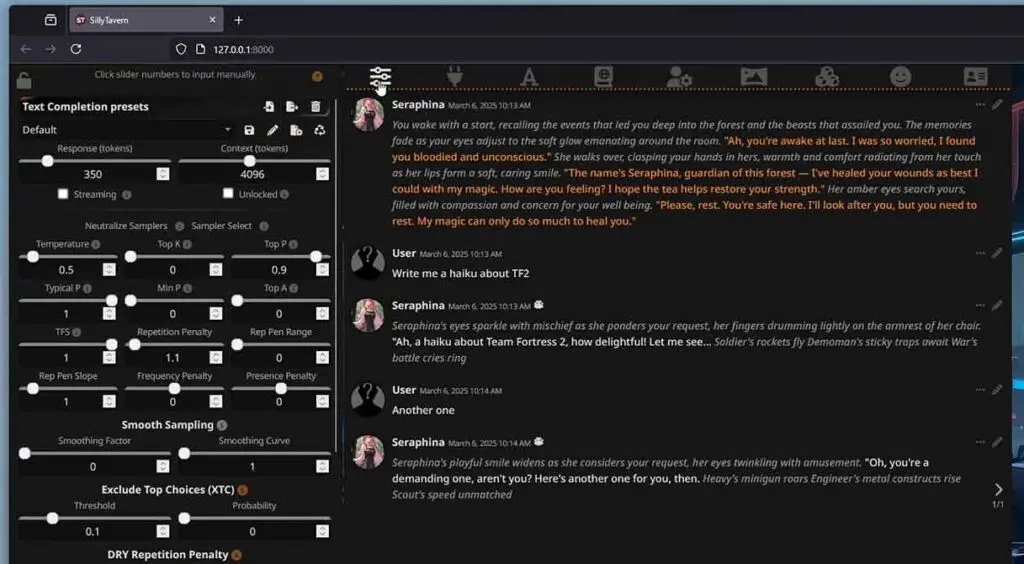
And now comes the time for the software made for all of you who want to gain easy access to a fully local and private character.ai alternative on your own computer. The KoboldCpp and SillyTavern combo is among the most commonly chosen options for this use case.
KoboldCpp is a software backend which you can use with any compatible UI you like, but it also features its own inbuilt graphical user interface for the impatient.
SillyTavern serves as a highly customizable frontend which can handle character cards, visually appealing modifiable conversation interfaces, and a lot of external extensions which can further enhance your local AI roleplaying experience.
Although the installation of the KoboldCpp and SillyTavern takes a little bit more than one click, it’s equally simple as dealing with LM Studio and Ollama if you follow a decent guide. And luckily, I’ve got one right here – you can be up and running in about 10 minutes of setup, see for yourself! – Quickest SillyTavern x KoboldCpp Installation Guide (Local AI Characters RP)
Other LLM Software Options – There Are Quite a Few
Aside from the options mentioned above, there are many different ways to go about hosting large language models locally, albeit they are in principle very similar to those already mentioned being either console-based inference frameworks, or full-fledged model hosting tools with mature user interfaces. Here are some more options you have.
- Jan – An inference client with a one-click installer and a simple user interface similar to LM Studio
- AnythingLLM – Another similar software with great RAG implementation and a large library of custom plugins and integrations
- Gpt4All – Inference ecosystem made by Nomic.ai with very similar feature set and capabilities
Once again, if you want to know about even more software like this, you can check my master list of all of the most popular LLM inference software for this year here: Local LLM Software Compatible With AMD & NVIDIA GPUs List
Memory Requirements, Types, & Formats of Local LLM Models
For fast GPU inference you want your model to fit entirely in your graphics card’s video memory (VRAM). The model’s size during inference consists of all of its parameters/weights, plus additional data needed for the model to run such as activations, KV-cache and so on. You can read much more about that here: LLMs & Their Size In VRAM Explained – Quantizations, Context, KV-Cache
The general rule of thumb with smaller context models is: take the size of your downloaded model file in GB, and add about 20% of overhead to estimate how much memory you need for inference.
If you don’t have enough VRAM in your graphics card, depending on your software setup you’ll be able to make use of GPU offloading – which is essentially letting the model accommodate some additional space in your main system RAM, in addition to your VRAM. This however, can slow down inference by a huge factor.
“What if your available VRAM just isn’t enough for the model you want to run? In these cases, you have options to offload some or all of the model data to your main system RAM. Many inference frameworks like Llama.cpp, and by extension local LLM software like LM Studio or KoboldCpp support this, allowing you to run models much larger than your available GPU VRAM, albeit with much slower performance.”
https://techtactician.com/llm-gpu-vram-requirements-explained/
If you’re not sure whether your selected model will be able to fit in your GPU memory or not, you can use one of many LLM VRAM calculators available online, such as the Apxml calculator to get even more accurate estimates.
You can learn more about these here: 8 Best LLM VRAM Calculators To Estimate Model Memory Usage
The most popular source for finding free, safe-to-use open-source LLMs is Hugging Face (HF). Now let’s talk a little bit more about the available model formats and types.
LLM Model Types, Formats & Quantization
Once you start browsing model repositories like Hugging Face for the first time, you’ll quickly notice that even the same model can come in many different versions, which often confuse beginners looking at an average HF repository model download page.
Here is a must-read before you continue: LLMs & Their Size In VRAM Explained – Quantizations, Context, KV-Cache
Base Models, Fine-tunes, and Merges
Open-source LLMs can be distributed in multiple formats and quantization levels, each with its own purpose and trade-offs. Three of the most basic main aspects you will see mentioned in terms of model types are base models, fine-tunes, and merges.
Base models are trained from scratch on general data and are like a “blank slate” AI brain, while fine-tuned models have been further trained on specialized datasets (for example, RP dialogue, programming, or medical texts) to make them better at certain tasks. Merges combine parts of multiple models to create something with the strengths of each parent.
Model Formats – GGUF, GGML, Safetensors
The next thing you will encounter is model file formats. The most common for local use right now are GGUF, GGML (older, now mostly replaced), and Safetensors.
GGUF and GGML are optimized for running models with CPU/GPU acceleration in inference software like KoboldCpp or LM Studio, while Safetensors files are typically used for model conversion, fine-tuning, or when loading models in frameworks and on hardware that doesn’t require quantized weights.
Quantization and Context-Length
Speaking of quantization, this is the process of reducing a model’s precision to make it smaller and faster to run on limited hardware (you can read more about that in the LLM VRAM requirements guide). You’ll see formats labeled as Q2, Q4, Q5, Q6, Q8, etc. Lower numbers mean more aggressive compression (faster and smaller, but less accurate), while higher numbers preserve more accuracy at the cost of VRAM and speed. Choosing the right quantization is about balancing your available hardware with the quality you need for your use case.
You also need to be aware of the context length differences between models. Context length refers to the maximum number of tokens a model can process and retain at once, determining how much text it can consider when generating a response.
Some models come with extended context windows (e.g., 8k, 16k, 32k tokens), allowing them to effectively “remember” more of the conversation or handle longer documents without losing track of your data. This comes at a performance and memory use cost, so make sure your hardware can handle larger context models before going in blind to try one out.
Model Types – Instruct, Chat, Completion, Code
You’ll also see models labeled as instruct, chat, completion, or code. These terms describe how the model was fine-tuned and what style of input/output it’s been optimized for.
- Instruct models are trained to follow explicit written instructions. They’re designed to give clear, direct answers or perform specific actions when given a command in natural language (e.g., “Write a short horror story set in a lighthouse”). They’re best for concrete, task-oriented workflows.
- Chat models are optimized for back-and-forth conversations, usually with formatting and safety tuning to keep a coherent persona over multiple turns. They tend to handle casual or roleplay-style interactions better and often maintain more conversational flow. These are also best suited for ChatGPT-like AI assistant use cases.
- Completion models are closer to the original GPT-style design. They simply predict the next chunk of text based on the given input, without an inherent instruction-following bias. They’re more “free-form” but require more careful prompting to get the desired results.
- Code models are fine-tuned specifically on programming data, such as GitHub repositories, coding tutorials, and Q&A threads. They are meant to be best at generating, explaining, and debugging code, usually in multiple programming languages.
Choosing the right model version for your workflow can make a surprisingly big difference in final output results, so make sure to experiment a lot! Let’s now get to some concrete examples of smaller models you can run on your setup, using the software of your choice.
Best Small Lightweight Local LLMs to Begin With
Here are some interesting smaller 7-8B models you can start out with. These should work on most setups in small context window conversations, even on older GPUs with 8GB of VRAM:
- OpenHermes-2.5-Mistral-7B
- Meta-Llama-3.1-8B-Instruct-GGUF
- Wizard-Vicuna-7B-Uncensored
- Dolphin-2.9.1-Llama-3-8b
Of course if you have enough GPU memory to spare, you can start out with larger and therefore more powerful versions of these models (12B and up) which you can find in their main repository pages you can get to through the pages linked above.
Make sure you try a few different models right after installing your very first inference software. Different LLMs with the same parameter count can vary by a lot in terms of:
- Their general logical reasoning capabilities.
- Level of censorship (if any is present) and inherent “guidance” towards certain types of replies.
- Capabilities of handling longer context conversations.
- General default response style and structure.
- Responsiveness to guided in-context training.
- Knowledge on certain topics (there exist many open-source models specifically trained/fine-tuned for certain knowledge fields or towards expertise in a chosen topic).
I would wager that there are many more worthwhile quality models to try out right now than you have free space on your drive. Once again, I really encourage you to try at least a few of them out.
Check out also: My 7 Best 7B LLM Models For OobaBooga – AI Roleplay & Chatting
Multimodal Models With Vision Capabilities
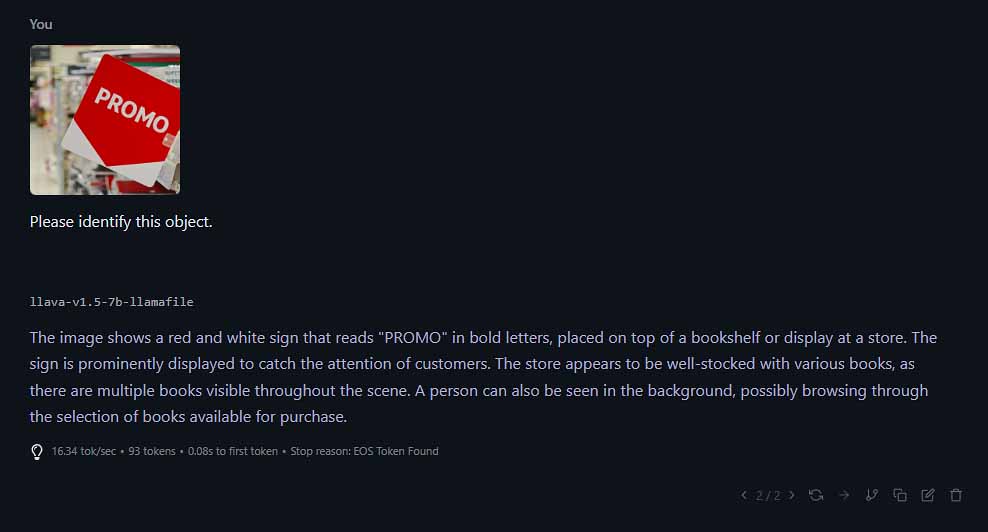
Did you know that there are also some multimodal models that can actually process and “understand” the contents of images that you’re showing them similar to how ChatGPT does? Here are two of the best open-source vision-enabled large language models I had the pleasure of testing out:
Remember that to use vision-enabled models you need your chosen inference software to support them. A great example of software that does have support for multimodal LLMs is LM Studio. Take a look for yourself: How To Import Images In LM Studio – Local AI Image Description
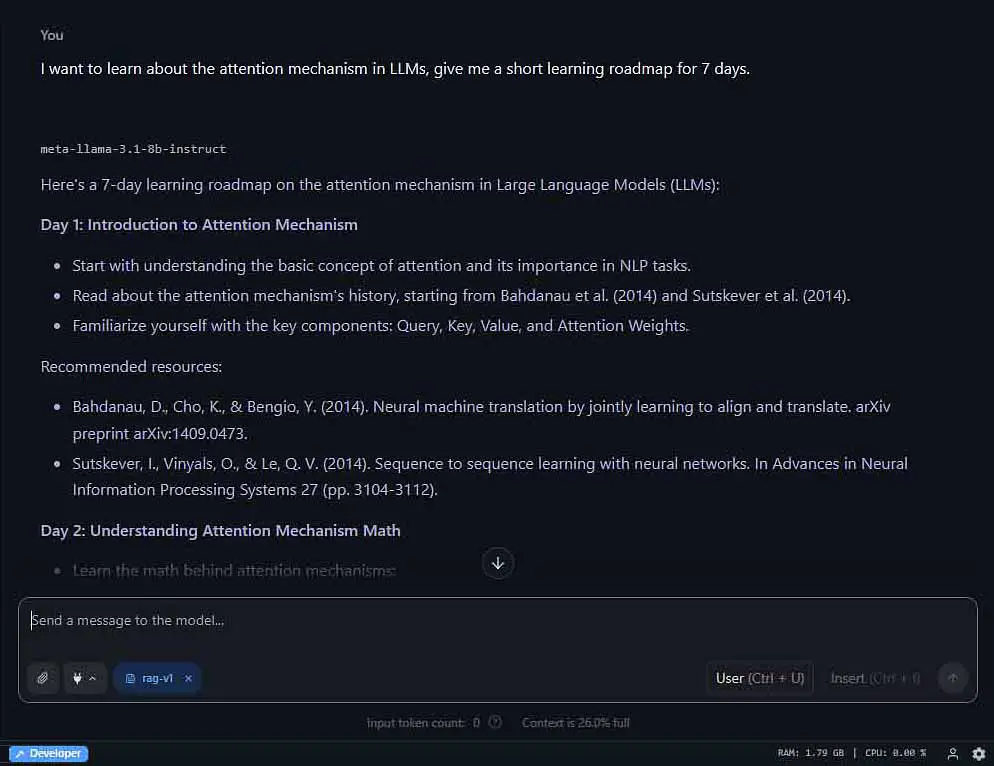
Local LLM RAG – Chatting With Your Documents
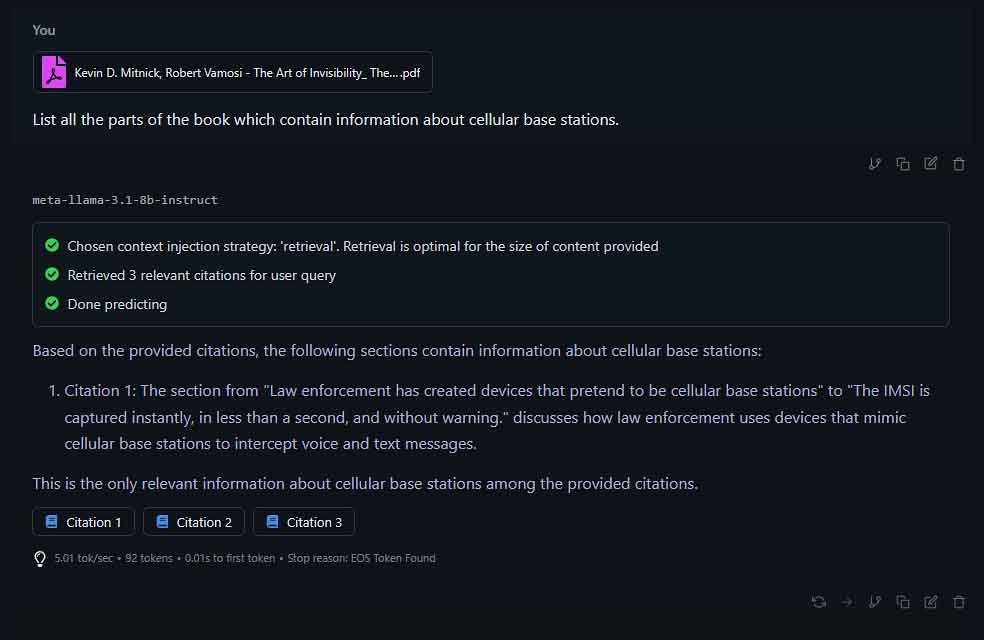
Retrieval Augmented Generation (RAG) is simply enabling your model to process externally supplied data sources such as text files or documents to be able to expand its knowledge and answer according to the contents of said files.
Software such as LM Studio (with its “Chat with Documents” functionality) or OobaBooga Text Generation WebUI (with the “web_rag” extension) has excellent RAG implementations that can work surprisingly well, especially with larger models. This is another way you can enhance your local LLM experience and get more out of your locally hosted models.
Enable Internet Access for Local LLMs
Another great way to expand on the features of your local LLMs is letting them connect to the internet to help them reference new information oftentimes not present in their initial training data.
There are a few ways to go about internet connection when it comes to local LLM software, and they are all different depending on the actual software/frontend that you’re using. For instance, in LM Studio, one way you can go about it is setting up a connection to an external Brave MCP server.
SillyTavern on the other hand, used with any compatible backend has its Web Search extension, which can enable internet access for all chat completion sources that do not provide web search capabilities, and the OobaBooga WebUI can use the aforementioned “web_rag” addon for just that.
Where To Go From Here? – Other Equally Interesting Local AI Software
Once you dip your foot in the ocean of open-source AI software, it’s hard to resist exploring the topic some more, especially knowing that you are minutes away from free access to:
- Image generation software like Fooocus making use of free and open-source models such as Stable Diffusion and SDXL which can run on an average spec’d modern laptop
- Local AI voice changers such as the Okada Live Voice Changer
- AI voice cloning software letting you clone anyone’s voice with just seconds of recorded speech such as AllTalkTTS
- …and many others!
If you want to know some more about different kinds of local AI software and the hardware you need to run it, there are a lot of guides for you here on Tech Tactician. Thank you for reading, and see you next time!
We have a similar guide for local AI image generation models if you’re interested! Check it out here: Beginner’s Guide To Local AI Image Generation Software – How To Start This Year