
If you’re facing really low training speed using Kohya GUI for training Stable Diffusion LoRA models, check here for a set of possible fixes that have worked for me. Sometimes it’s the case you’ve been able to train your LoRAs faster some time ago and now suddenly it takes hours. There are just a few common reasons for that I’m aware of. Read on to learn more!
If you’re interested in optimizing your LoRA model training process and its final output, check out also: Kohya LoRA Training Settings Quickly Explained!
The Most Likely Cause – You’re Short On VRAM
If you’re running Kohya on an NVIDIA graphics card (and knowing how it goes with AMD and Stable Diffusion, you probably are), there was a pretty important driver update for most of the recent NVIDIA GPUs that changed one very important thing.
The driver version 536.40 to be specific, has introduced a feature that lets your GPU automatically utilize your system RAM for data processing when your VRAM runs out. As this offloading process is automated, you won’t be notified when it happens.
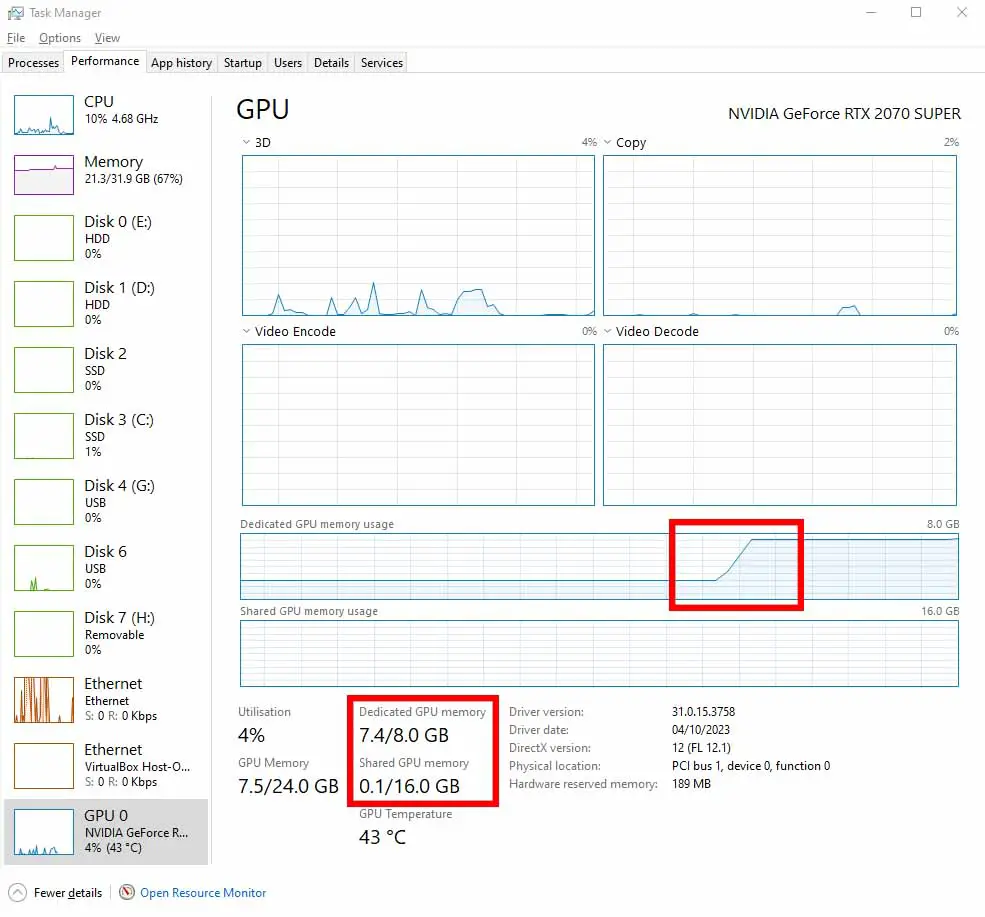
Now comes the important part. Once the offloading mechanism kicks in during a LoRA training process, the training data gets spread between your VRAM and your main system RAM. This causes a massive slowdown, as transferring the data between the GPU and RAM is a process that takes substantially more time than simply processing all the batch data “locally” within your graphics card. You can actually see this happening live in your task manager (on Windows) as shown below, or using a GPU stats viewing utility on Linux-based systems.
NVIDIA noticing the problem which hit many Stable Diffusion users and has caused a lot of confusion at first, have published a short official article explaining how to disable the shared memory fallback on your system, specifically made for users running Stable Diffusion models on ~6GB VRAM systems.
Once this feature is disabled, instead of continuing the training at ridiculously slow speeds, Kohya will throw a “CUDA out of memory” error, and let you readjust your training settings to fit within your GPU VRAM constraints, so that you’re able to train your model at full speed.
This issue was also discussed in detail in this Reddit post, so feel free to check it out if you want to see what the SD community has to say about that.
If you don’t want to disable this feature on your system and still want to prevent training slowdowns, read on!
By the way, here you can take a look at out my curated list of the best graphics cards for both Stable Diffusion and local LLM hosting. With these, you’ll never run out of VRAM! – Best GPUs For Local LLMs This Year (My Top Picks!)
How To Monitor Your VRAM Usage During Training
This segment is for all of you who don’t want to disable the NVIDIA shared memory fallback feature on your system (including me).
To make sure that you won’t run out of VRAM during the training process, you need to have a way of monitoring the video memory usage. This will be different on Windows and on Linux-based systems. In this guide, I’ll focus on the Windows approach.
Open the Windows task manager and go to the GPU tab. There, you will see two indicators – one showing you the current VRAM usage (Dedicated GPU memory), and another one, showing the amount of data that gets offloaded to the system RAM (Shared GPU memory) once you run out of VRAM.
In 99% of the cases, you don’t want any data getting offloaded to the “Shared GPU memory” when you’re training a LoRA model. Why? As I’ve already mentioned, just because once the training process starts relying on transferring data from the shared GPU memory (RAM) to the GPU (and the other way around) because of VRAM shortage, you will face severe slowdowns.
If you don’t yet know how exactly the “Shared GPU memory” works on Windows, I strongly advise you to quickly go over this short explainer here: What Is The Shared GPU Memory In The Task Manager?
While on Windows, monitoring your VRAM usage is rather simple with the task manager, as shown on the image above. On Linux it’s a little bit different.
On most Linux-based systems, you can either use the NVIDIA System Management Interface with the command nvidia-smi -l 1 if you’re using an NVIDIA GPU, or use a neat and nicely readable wrapper for it, like gpustat to see your current live GPU stats including the VRAM usage, updated in real-time.
If you want to know more about viewing your graphics card statistics on Linux (AMD cards included), check out this short article here, which explains: How To See Current GPU VRAM Usage On Linux? (NVIDIA & AMD)
Kohya GUI Slowing Down During Training – Possible Fixes
If you’ve ever experienced Kohya GUI suddenly starting to train your models extremely slow, or slowing down to one step every few seconds when the training was going reasonably fast before, this is in 90% of the cases caused by your GPU running out of VRAM, you not noticing it, and the training data getting offloaded to system RAM in the background.
There are essentially just two main ways to prevent that from happening and being able to train your models at full speed again:
- If you have any software or apps that use up a lot of VRAM open, close all of it – These are most commonly by my own experience things like: Photoshop with a project open, a video game running in the background, a bunch of tabs with YouTube videos open, a Twitch stream running on the second monitor, and so on. Figure out what’s eating up your VRAM, and close the problematic apps. You can monitor the current VRAM usage in the task manager as shown above, so you have a way of immediately verifying if what you’re doing is working.
- Make sure that your training settings are set in a way that is appropriate for the amount of VRAM available on your GPU – Below I list a few quick examples, but this article also goes in depth of different available Kohya GUI training settings. The bottomline is: applying the right settings you can train quality LoRA models even on a GPU with less than 8GB of VRAM, but these settings will depend on your particular trained model context, so there cannot exactly be a one-fix-all preset solution provided here. Kohya offers you a lot of “VRAM/training speed tradeoff” settings, and in many cases changing them does not really affect your final model quality.
While tweaking the training settings can only be done after terminating the current training process, changing the settings and then beginning the training again, finding and ending the VRAM hungry processes can be done live when the training is going on. If you’re lucky enough and you have freed up enough video memory, the training should speed up without you having to restart it.
In some rare situations, if your training slowdowns are caused by a thing different from VRAM shortage, these fixes might not work. However, in my experience, video memory limit issues are almost always the case for a LoRA model being trained too slow even with a capable GPU.
LoRA Training Settings That Affect VRAM Use
The VRAM usage during the LoRA training process is determined by quite a few factors, a few of which are completely under your control. Tweaking some of the settings before beginning the process can limit the VRAM use and help keep it within the limits of your graphics card.
Chances are, that you’re using a settings preset to initiate your training. This is all good, however you really should learn what the basic training parameters do before attempting to optimize the whole process. It can give you a much better understanding of what’s happening in the background.
The settings which affect the VRAM use the most are most importantly: first – the training batch size, then – the max resolution, and after that – the optimizer you choose. Tweaking them in the right way can help you ensure you’re not using more GPU memory than you actually need to when training your model.
For instance, when it comes to optimizers, the AdamW8bit and AdaFactor are said to be the less VRAM-hungry options. The training batch size on low VRAM systems should be set to either 1 or 2 (lower = less VRAM used), and if you don’t have a lot of video memory to spare, you most likely should not attempt training a LoRA on images larger than 512×512 or 768×768 (again lower = less VRAM used). Reducing your network rank and/or network alpha accordingly can also help quite a bit. Again, it all really depends on your system and the output you wish to achieve.
If that doesn’t sound that familiar to you at all, you can (and you really should) read this short article about all the Kohya GUI LoRA training settings if you want to improve both your training times and model quality. All of these settings are better explained in there.
If you’re in a hurry, I suggest you just ctrl+f search the word “VRAM” in the mentioned post and see which settings affect its use the most and how to set them right in your situation!
See it here: Kohya LoRA Training Settings Quickly Explained – Control Your VRAM Usage!
What About SDXL LoRAs?
SDXL model LoRAs are in my experience pretty tricky to train on 8GB VRAM systems, and next to impossible to efficiently train on setups with less than 8GB of video memory. These should be trained on 1024×1024 images, as the base SDXL model was trained on exactly that, and this of course further adds to the VRAM requirements for the training process.
As with regular Stable Diffusion 1~ and 2~ based LoRA models, when attempting to troubleshoot slowdowns when training SDLX LoRAs, check your VRAM usage during the process and refer to the fixes mentioned in this article.
Other Driver / Software Related Issues

I bet many of you reading this article are currently on different version of NVIDIA drivers than me, have different NVIDIA Control Panel settings going on, and overall are rocking vastly different PC setups.
This means that if you’re unable to optimize your training process despite using the methods mentioned here, it might be one of two different cases. The first thing would be simply that your setup isn’t powerful enough for what you’re trying to do and the training will be slow regardless of what you do, or your GPU does not have a sufficient amount of VRAM for your particular needs.
The second reason could be that there is another software/driver issue at play that makes you unable to correctly incorporate appropriate fixes mentioned, or that your slowdown issue isn’t at all VRAM related. If that’s the case you can do 3 things before you consider giving up:
- Restart your PC (as stupid as this might sound, if you’re one of the people who do not often turn off their PC and only let it snooze for a bit overnight, a quick system restart might fix quite a lot of your issues).
- Update your GPU drivers to their latest version – a pretty straightforward fix, be sure to source your drivers from the official NVIDIA website.
- Fall back to the latest drivers version where everything was working fine – as a last resort, this might just work for you if you’ve been able to train your LoRAs reasonably fast before.
After that, you can reconsider your goals with LoRA training and attempt to train at a lower resolution, etc., or wait until some optimizations on the software side will be introduced either on the Kohya or NVIDIA side. That’s pretty much it!
Ooor… upgrade your GPU! Dig some high VRAM graphics cards here: Best High VRAM GPUs For Local LLMs This Year (My Top Picks!)
And most importantly, read this: Kohya LoRA Training Settings Quickly Explained It’s really worth your time!