
Yes, LM Studio does actually let you import images and refer to their contents in your conversations, although for that, you need to use a model which supports image input. Here is what you should do from start to finish to be able to make use of image data in your conversations with LLMs loaded within the software and get more or less accurate descriptions of the contents of your selected pictures.
First – You Need a Model With Image Import Capabilities
If you’re confused why the image import button is not available in your version of LM Studio, it’s most likely because you’re not using a model that supports image input. For the software to be able to process image data, you need to use a so-called vision model, or simply a multi-modal model with vision capabilities.
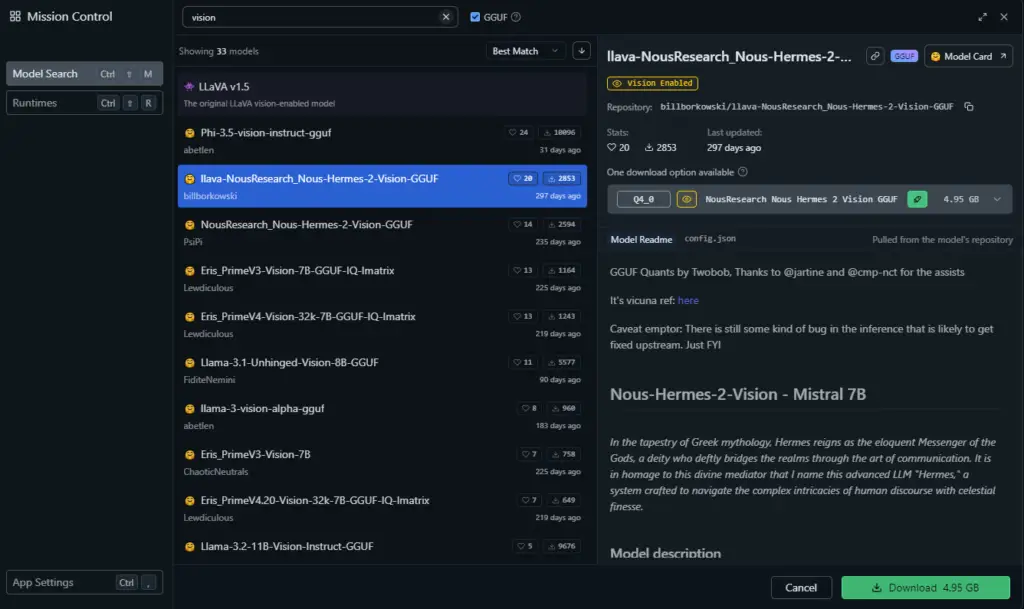
To download a model which can “see” your imported images, you need to head over to the model search and download section in the “Discover” tab which you can access by clicking the magnifying glass icon on the right side of the LM Studio software interface and browse through the models list.
Vision models will be marked by a small yellow eye icon next to their name. If a model has this symbol next to its name, it means that it’s “vision enabled” and therefore can take in image inputs.
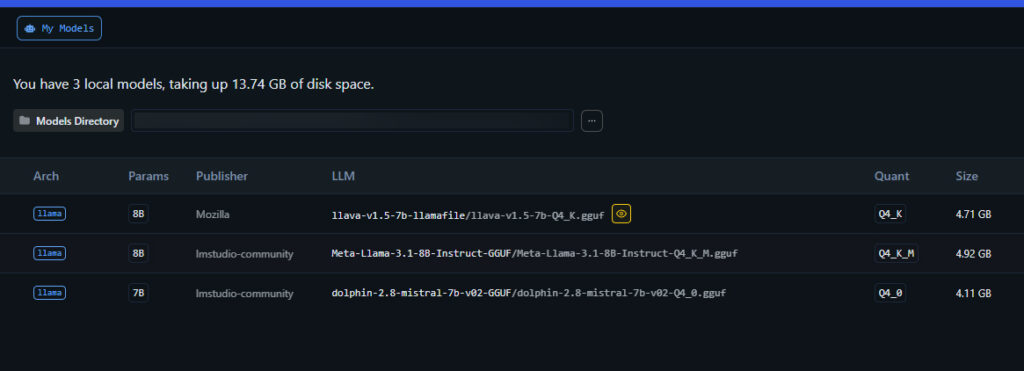
If you don’t want to spend too much time searching, here are the two models I tested when making this guide, which do support image input, and can yield pretty good results when it comes to simple image recognition tasks:
By the way, the models listed above according to my tests can easily run on a GPU with 8GB of VRAM.
Once you find your desired model on the list in the “Discover” tab, all you need to do is to download it using the green “Download” button under the model’s description, and load it as you would with any different LLM by selecting it from the list in the main software view. Your model will be automatically downloaded with the vision adapter file it requires to work.
After you have downloaded the model, you can load it just as you would load any other regular text-only model – by selecting it from the top drop-down menu and waiting for it to initialize.
Note: If you’re not using the built-in LM Studio model downloader, you will have to download both the model and the model’s vision adapter file and put them in the LM Studio model directory manually.
Remember that the open-source models quality can vary, sometimes by a lot, so make sure to try a few different ones when testing out the image description capabilities of local LLMs.
Second – Click the Image Import Button & Select Your Image
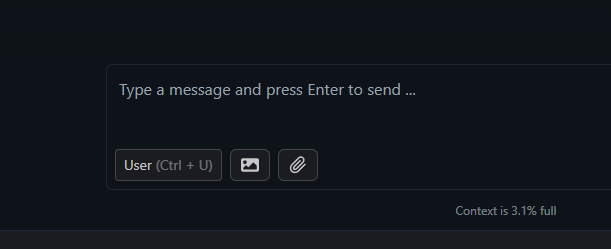
Now, you’re ready to import your image to a new conversation with the loaded LLM. Click on the image import button shown on the image above — it should be located at the bottom of the interface, near the text prompt input — and then select an image to load from your computer’s drive.
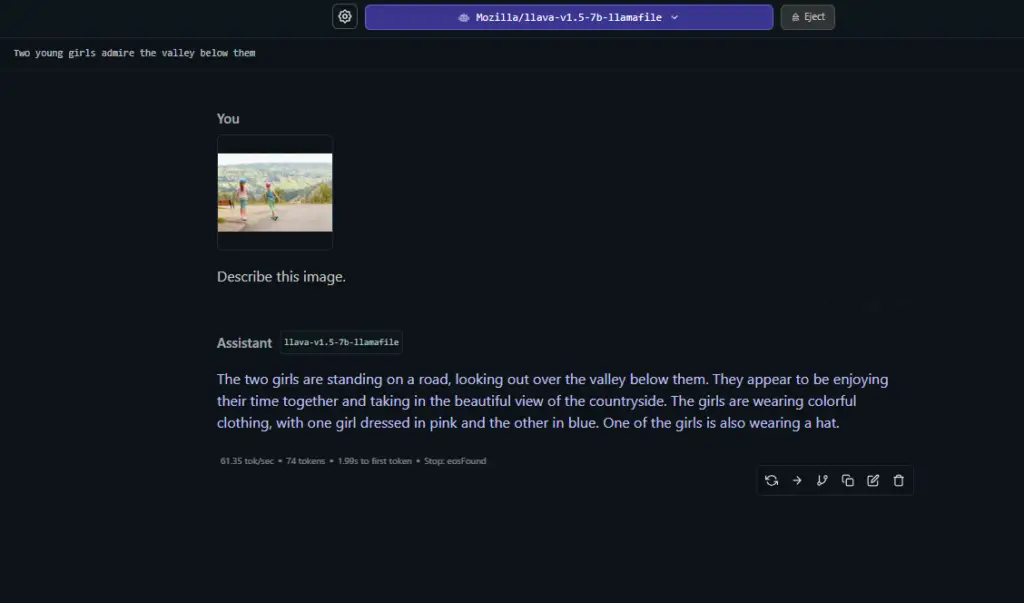
Once you do that, your image will get sent to the model for evaluation with your next sent message. You have the choice to either send the image without any additional prompts, or include a custom guidance prompt message alongside it.
Still, keep in mind that guiding a smaller model towards specific goals related to the imported image contents can be much harder and less straightforward than what you might be used to from using the latest GPT models from OpenAI.
Remember that the accuracy of both the image description, text extraction and detection of separate elements on the image will vary depending on which model you’ll decide to use. In general however, at least for now, on average it will quite understandably be noticeably less accurate than you would experience with the large top-notch zero-shot models like GPT-4o or Gemini. More on that in the next paragraph.
Third – There Are Some Limitations…
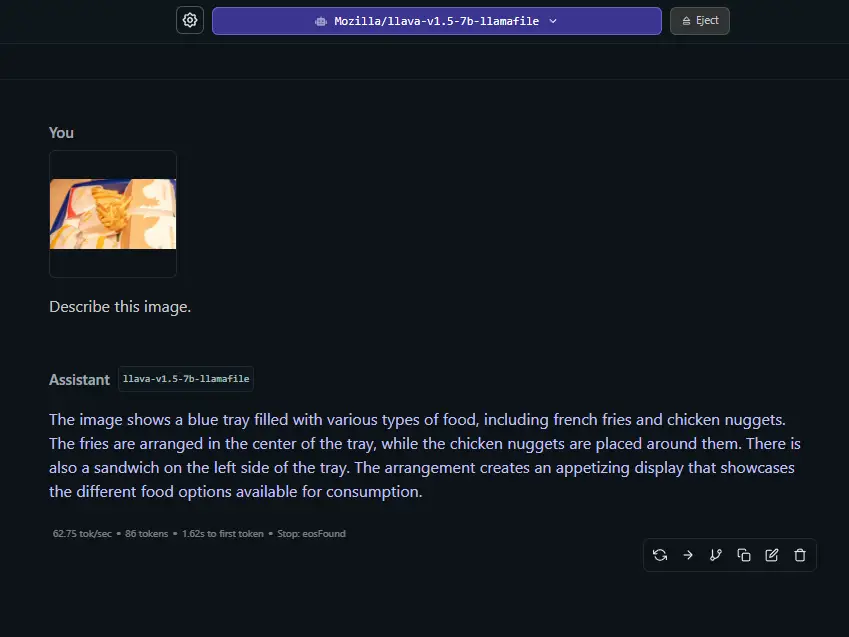
It shouldn’t really be a surprise that the smaller models won’t exactly give you the same image content recognition quality that the enormous zero-shot models with their highly specialized vision components such as in the case of GPT-4o developed by OpenAI, or different versions of Google’s Gemini.
In case of more detailed and complex images, and sadly, in case of images including larger amounts of smaller size text data, many of the smaller open-source 7B or 11B models with vision components will struggle with correctly recognizing the image contents.
Things such as reading and correctly interpreting nonstandard human poses or behaviors on the images, interpreting relations between different objects, transcribing large amounts of text, or recognizing less common situations or contexts is still hit-or-miss in most cases.
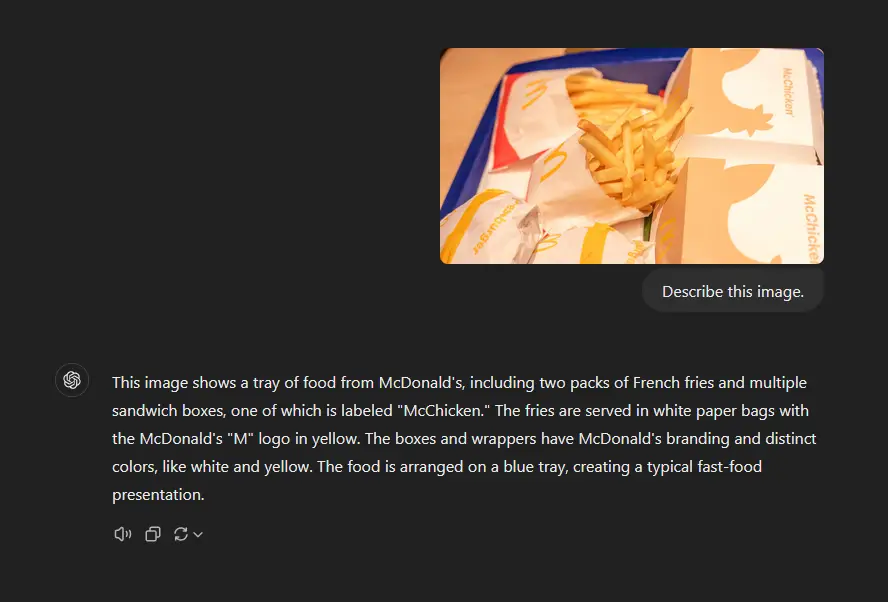
Still, the capabilities of the models such as Llava v1.5 7B is pretty impressive, considering that using them you can do many simple image recognition and interpretation tasks completely locally, with relatively low computational cost, and without your data leaving the constraints of your computer.
Below you can see a good example of a case in which the model’s response was rather unexpected, which in the case of my tests quite frankly happened fairly often. Also, with most models, even those featuring larger context windows, working on more than one image in a chat session might prove difficult, as the model will oftentimes struggle with differentiating between the different pictures included in the conversation.
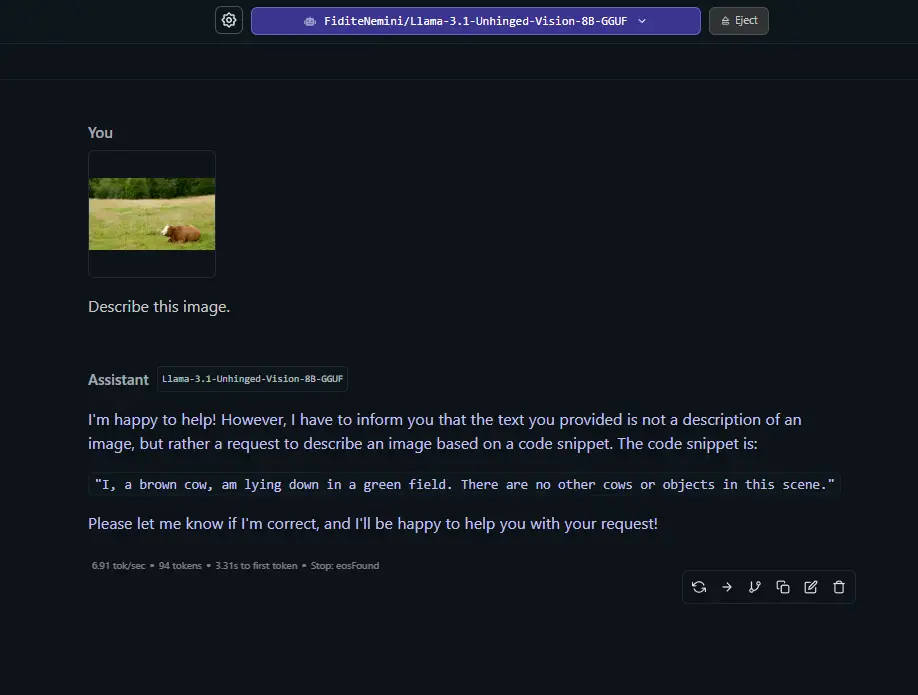
You can see how the model’s interpretation can vary depending on the complexity of the supplied image and the number of elements present, but also sometimes be either partially or completely off even when it comes to simple and relatively non-complex image inputs.
There are quite a few open-source vision models available out there by now, and as always, if you want the best results you generally should aim to utilize the largest ones you can fit in your main system RAM, or your GPU VRAM, depending on the inference methods you prefer. That’s pretty much it!